
STAGE 2
Background: Computer Architecture
- Instruction Set Architecture: CPU가 사용하는 명령어와 관련된 설계. CPU가 해석하는 명령어의 집합.
- 가장 널리 사용되는 ISA: Intel x86-64, ARM
X86-64 Architecture=AMD64 Architecture
x64 아키텍쳐의 레지스터
- General Register
- 주용도는 있지만, 그 외의 다양한 용도로 사용될 수 있는 레지스터.
- 32비트 아키텍쳐 CPU가 제공할 수 있는 가상메모리의 크기: 4GB
- 64비트 아키텍쳐 CPU가 제공할 수 있는 가상메모리의 크기: 16EB(엑사바이트)-어마어마하게 큰 공간으로, 프로세스의 성능에 제한을 걸 일이 없다.
- x64의 경우 각 범용 레지스터에는 8바이트 저장
-
이름이 r로 시작함-64비트 아키텍쳐. 32비트 아키텍쳐는 e로 시작함.
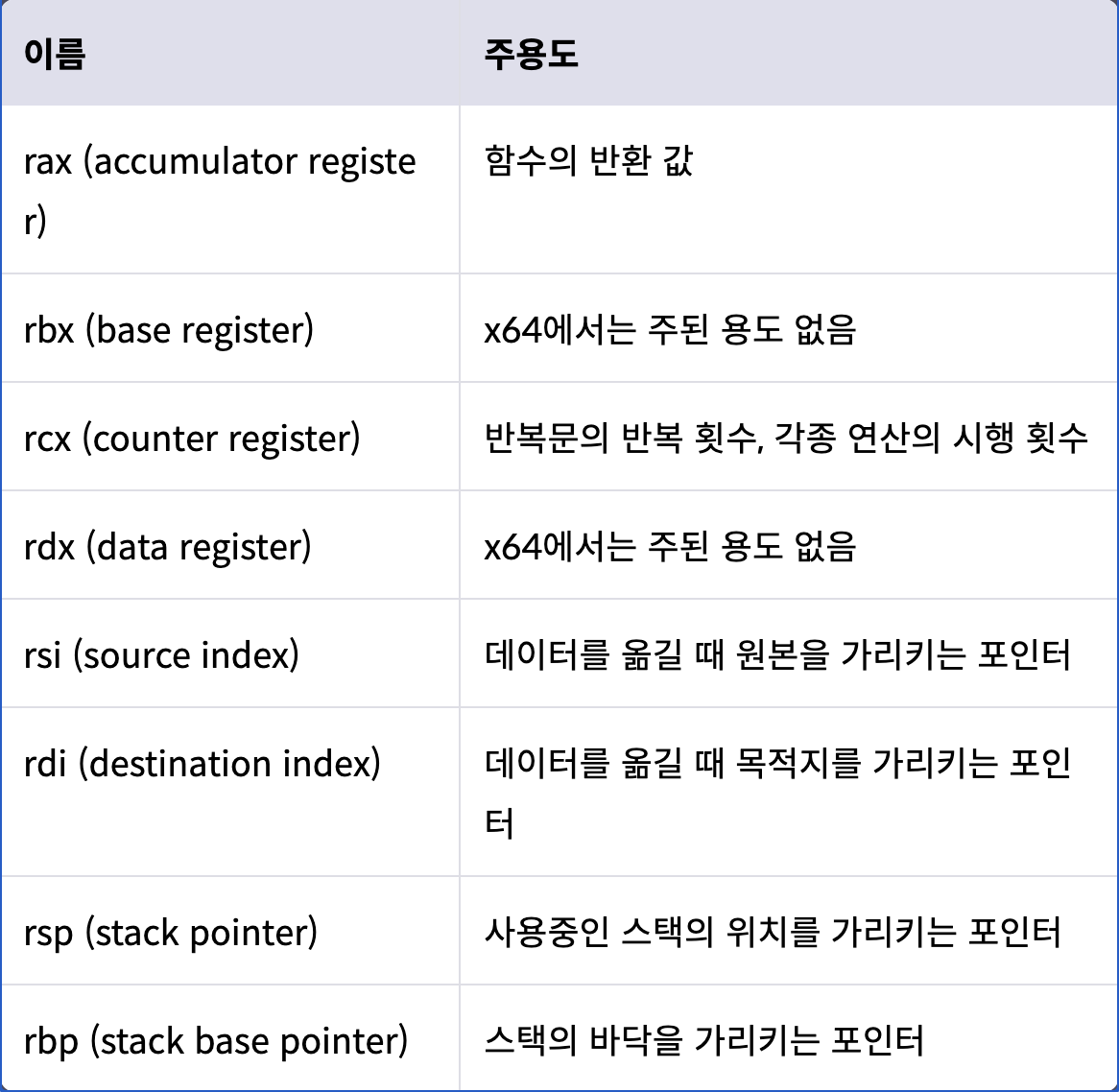
x64의 general register중 주용도가 정해진 레지스터들.
→ ebx는 rbx와는 다르게 메모리 주소를 저장하기 위한 용도로 사용됐었음.
→ edx는 rdx와는 다르게 부호 관련한 명령을 저장하기 위한 용도로 사용됐었음.
- 주용도는 있지만, 그 외의 다양한 용도로 사용될 수 있는 레지스터.
- Segment Register
- 6개 종류: cs, ss, ds, es, fs, gs
- 64비트로 아키텍처 확장되면서 용도에 큰 변화가 생김.
- 32비트 시절… general register 크기가 작으니 사용 가능한 메모리 주소 폭도 좁았음.
- 따라서 오프셋에 필요한 세그먼트 주소를 저장해 주기 위해 사용됐었음.=사용 가능한 메모리 주소 폭을 늘려 줬음.
- 실제 주소 = 오프셋 주소 + 세그먼트 주소
- 그런데 64비트 구조가 되면서 사용 가능한 메모리 주소 폭이 매우 넓어짐.
- 따라서, 이젠 주소를 간접적으로 표현해 주기 위해 사용하는 일이 없어짐.
- x64에서 cs, ds, ss는 코드 영역, 데이터, 스택 메모리 영역을 가리킬 때 사용됨.
- 나머지 레지스터는 운영체제 별로 용도를 결정할 수 있도록 범용적으로 제작되었음.
- Instruction Pointer Register
- 다음에 실행할 instruction 가리키기.
- x64: rip(8 byte), x86-64: eip(4 byte)
- Flag Register
- 프로세서의 현재 상태를 저장하고 있는 레지스터.
- x86: 16 bit → x64: 64 bit, “RFLAGS”
-
RFLAGS는 64개의 플래그를 사용할 수 있지만, 실질적으로는 오른쪽 20개 정도 비트만 사용.
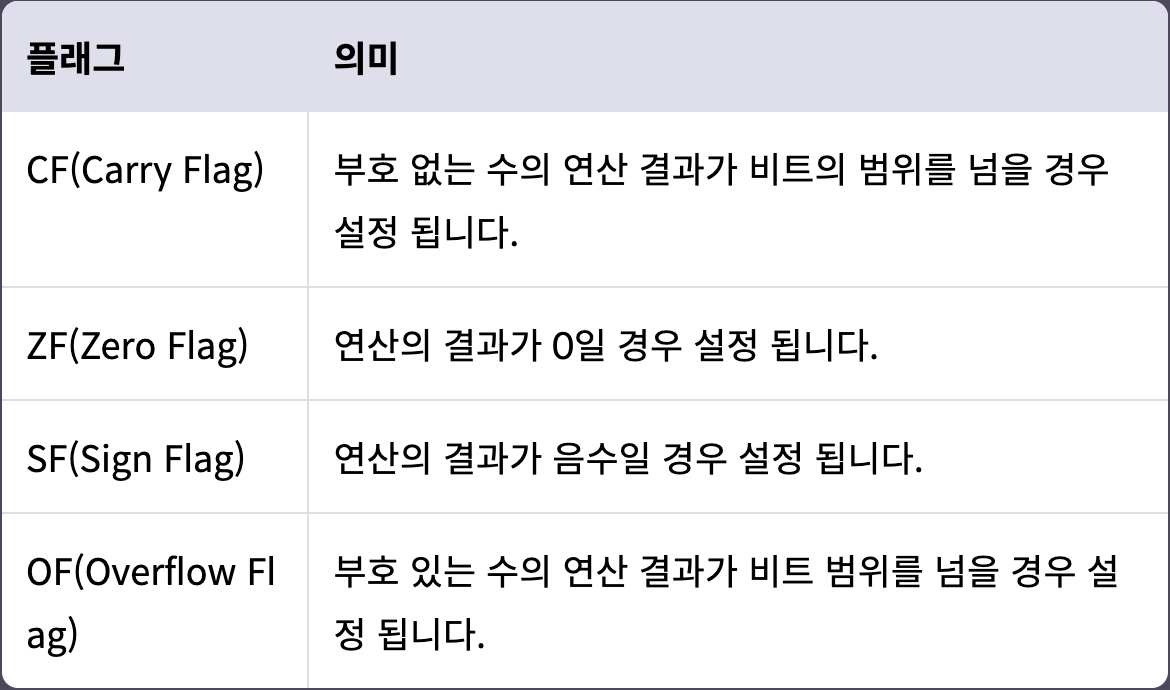
시스템 해킹을 할 때 주로 접할 플래그
레지스터 호환
16비트 아키텍처: 앞에 아무것도 안 붙음
32비트 아키텍처: 앞에 e 붙음
64비트 아키텍처: 앞에 r 붙음
예시: ax(eax의 하위 16비트) < eax(rax의 하위 32비트) < rax
그 와중에 16비트 아키텍처의 레지스터는 eax의 상위 8비트, 하위 8비트를 차지하는 것도 있음. (AX, BX, CX, DX 계열 중 끝이 H면 High로 상위 8비트, L면 Low로 하위 8비트)
Background: Linux Memory Layout
- Memory Corruption: 공격자가 악의적으로 조작한 메모리 값에 의해 CPU가 잘못된 동작을 하게 되는 공격. 시스템 해킹의 공격 기법의 기본이 되는 기법.
- Memory Corruption을 이용한 취약점의 종류:
- Stack Buffer Overflow
- Off by One
- Format String Bug
- Double Free Bug
- Use After Free
리눅스 프로세스의 메모리 구조
“5개 Segment”
적재되는 데이터 용도별로 메모리의 구획을 나눈 것.
- 리눅스에서 프로세스의 메모리를 구분하는 방식.
- 1) 코드 세그먼트, 2) 데이터 세그먼트, 3) BSS 세그먼트, 4) 힙 세그먼트, 5) 스택 세그먼트
- 구획별로 권한이 다르고, CPU는 해당 구역에 부여된 권한에 맞는 행위만 할 수 있음.
- READ
- WRITE
- EXECUTE
- 더 자세히 알고 싶다면, 세그먼테이션 기법 && x86-64 하드웨어 설계 참고.
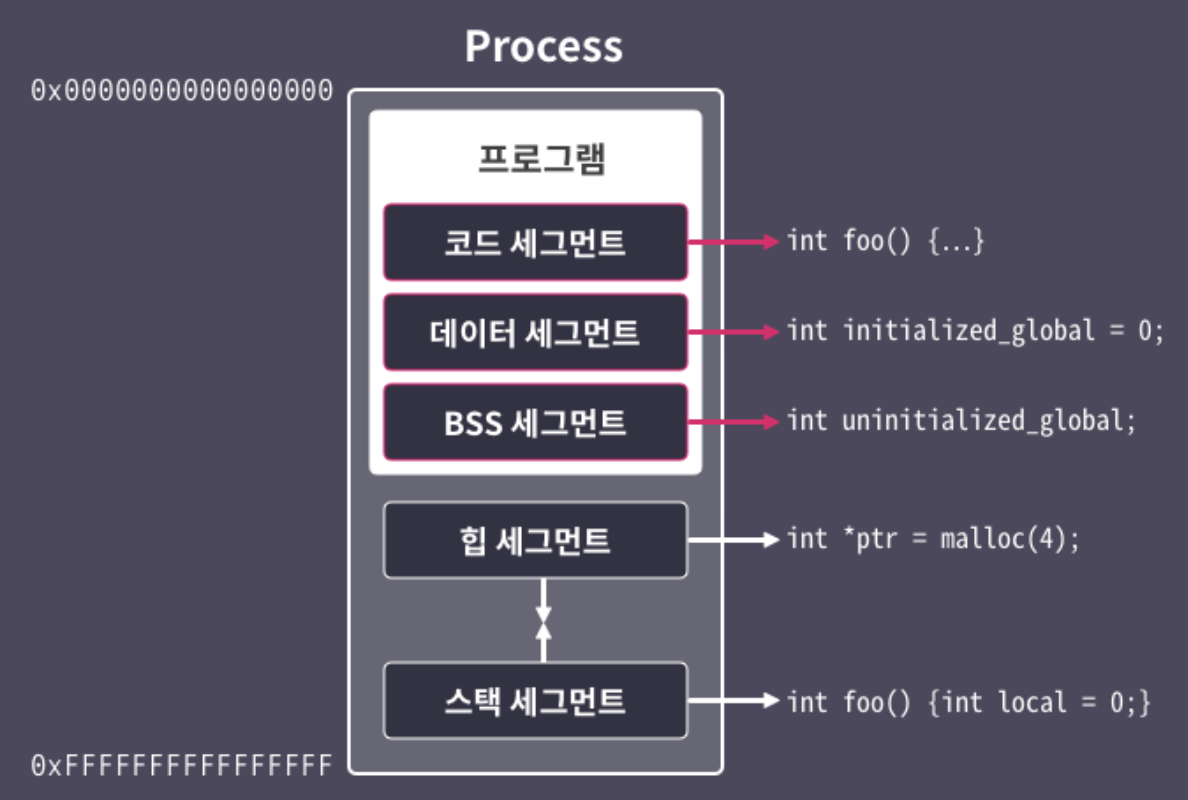
우와~ 리눅스에서는 실행 중인 프로세스의 메모리가 5개의 영역으로 구분되고, 각 영역별로 CPU가 부여받은 권한이 다르구나!
“Code Segment”
실행 가능한 기계 코드가 위치하는 영역
- READ & EXECUTE: CPU가 코드를 “읽어서” “실행”해야 하므로.
- WRITE 권한이 절대 있으면 안되는 영역: 악의적인 코드를 “쓰면” 안 되니까.
“Data Segment”
컴파일 시점에 값이 정해진 전역 변수 & 전역 상수가 위치하는 영역.
- Initialized Global
- READ + (상황에 따라 WRITE)
- 데이터 세그먼트에는 두 종류가 있음.
- Data Segment
- WRITABLE: 프로그램이 실행되면서 값이 변할 수 있는 데이터들. 예) 글로벌 “변수” 등…
- ROData Segment: Read-Only
- Non-WRITABLE: 프로그램이 실행되면서 값이 변하면 안 되는 데이터들. 예) 글로벌 “상수”
“BSS Segment”
컴파일 시점에 값이 정해지지 않은 전역 변수가 위치하는 영역.
- Block Started by Symbol Segment
- Not Initialized Global; 선언만 하고 초기화는 안한 전역 변수들
- 프로그램 시작 시 모두 0으로 값이 초기화됨.
- READ + WRITE
“Stack Segment”
프로세스의 스택이 위치하는 영역. 함수의 인자, 지역 변수 등의 임시 변수들이 ‘프로세스 실행 중’에 저장되는 공간.
- READ + WRITE
- “스택 프레임(Stack Frame)”이라는 단위로 사용됨.
- 함수가 호출될 때 생성되고, 반환될 때 해제됨(우리가 익히 아는 그것)
- 프로그램의 코드 플로우를 정확히 예측하는 건 불가능하므로, 스택도 가변적으로 할당됨.
- 작은 크기의 스택 세그먼트를 먼저 할당해 주고, 부족해지면 확장.
- “아래로 자란다”: 높은 주소→낮은 주소로 확장.
“Heap Segment”
힙 데이터가 위치하는 세그먼트. 메모리 할당 시 할당된 메모리가 저장된다.
- READ + WRITE
- 스택과 동일하게 실행중에 동적으로 할당된다.
- 리눅스에서는 스택 세그먼트와 반대 방향으로 자란다: 낮은 주소 → 높은 주소로 확장.
- 할당된 메모리가 저장된다: C언의 경우 malloc(), calloc()등으로 할당받은 메모리가 저장된다.
Q. 힙과 스택 세그먼트가 자라는 방향이 반대인 이유?
A. 동일하면 충돌하니까. 따라서 리눅스는 스택 베이스를 메모리 끝에 위치시키고 힙 베이스는 낮은 주소에 위치시켜서 충돌할 일이 거의 없게 만들어 놨음.
