
0. Golang이란
0.1. Golang의 특징
개발이 가능한 수준으로 공부하고 싶다면 이 공식 홈페이지를 참고하길
gdb로 go 바이너리를 동적 분석하고 싶다면 이 공식 홈페이지를 참고하길
0.1.1. 개요
- 프로그램 { 패키지 { 함수 } }의 구조를 가짐
- 즉, package main 내의 func main 이 컴파일되면,
main.main심볼을 가지게 됨 - Go 런타임은 Golang의 Concurrency를 기존 OS에서 제공하는 프로세스 관리 기능보다 훨씬 효율적으로, 컨텍스트 스위칭 비용을 적게 지불하면서 보장하기 위하여 구현됨
0.1.2. 동시성 지원(Concurrency, 링크)
고루틴
- Go가 제공하는 경량 스레드(OS단에서 제공하는 LWP, Light Weight Process를 사용자 단에서 구현한 개념)
- 함수 호출 앞에
go를 붙이면 해당 함수는 고루틴으로 실행됨(go {function_name})
채널
- 고루틴 간 데이터 통신을 위해 사용되는 구조체
- 채널은 버퍼를 가질 수도, 버퍼를 가지지 않을 수도 있음
- make로 채널을 생성하고, <- 연산자로 데이터를 송수신함(
ch:=make( chan string) \n msg:= <-ch)
여러 채널의 데이터 송수신 지원
- 여러 채널의 데이터 수신을 동시에 기다리되, 데이터가 먼저 도착하는 채널을 채택하는 기능 구현
-
이는 select 문으로 구현되는 개념
func main() { ch1 := make(chan string) ch2 := make(chan string) go func() { ch1 <- "Message from channel 1" }() go func() { ch2 <- "Message from channel 2" }() select { case msg1 := <-ch1: println(msg1) case msg2 := <-ch2: println(msg2) } }
고루틴 간 동기화
- 모든 동시성 프로그래밍이 그렇듯, 지정된 그룹의 고루틴이 끝날 때까지 기다리는 기능 / 뮤텍스 제공 / 특정 작업이 한 번만 실행되도록 제한하는 기능을 제공함
- 이는
sync패키지를 사용하면 구현할 수 있음
고루틴 스케줄링(더 자세히 알고 싶다면 링크로)
이 내용은 그림과 같이 보는 게 더 이해가 쉬우니, 위에 제시한 링크로 들어가서 읽어보는 걸 추천한다.
- 고루틴은 Go 런타임 스케줄러에 의해 스케줄링됨
- OS 단에서 스레드 스케줄링을 할 때를 참고해 보면, 유저 단에서 어떻게 고루틴 스케줄링을 추상화하여 구현했는지 알 수 있음. 즉, 유저 단에서 원하는 스케줄링 방식을 커널 단에서 실제로 실행해줄 수 있게끔 API 역할을 하는 게 Go 런타임 스케줄러임
- 기본적으로 N:M 구조로 스레딩이 되고, 현재는 local runqueue 방식으로 멀티코어 스레딩을 지원하며 할당된 local runqueue에 작업이 없으면 그때 global runqueue에 접근해 작업을 가져오는 혼합 방식을 취한 것으로 보인다.(멀티프로세서 스케줄링 방식에서 각 프로세서가 내부 코어별로 스케줄링 큐를 두는 per-core run queues 방식과 비슷함)
- 추가로, work stealing이라는, 운영체제에서의 Lord Balancing(Push & Pull Migration)과 비슷한 개념을 가져와 효율적인 시간 자원 배분을 꾀했다.
- 그러나 이 경우 시스콜로 인해 block 상태에 빠진 OS 스레드가 local runqueue를 가져버리면 Go에서 사용 가능한 OS 스레드의 개수를 정의하는 변수인 GOMAXPROCS가 정의하는 사용 가능한 OS 스레드의 정의와 충돌이 발생하여, 스레드 스케줄링의 주요 요소가 프로세스의 관리를 벗어나 버리는 상황이 발생한다. 즉, work stealing의 올바른 실 구현이 불가능해진다.
- 위 문제의 핵심은 block 상태인 OS 스레드(M)가 local runqueue를 가져버리는 예외 상황으로, 이 상황의 관리를 위해 신규 구조체(p-processor) 개념을 도입하여 p-processor가 local runqueue를 가지고, OS단의 기능인 OS 스레드(M)가 p를 상호간에 토스하도록 했다.
- 이 뒤로도 starvation의 방지, convoy effect의 방지를 위해 Preemptive Scheduling(시분할로 통제되는 자원선점)를 적용하며 그 구현책으로 go runtime 내에 sysmon 데몬 쓰레드를 구현하였다.
- sysmon 데몬 쓰레드는 고루틴들을 모니터링하고, M에 의한 실행 시간이 10ms를 초과한 고루틴을 잡고 있는 M에게 SIGURG 시그널을 보내 해당 고루틴을 Global runqueue로 보내도록 하는 방안을 채택했다.
- 추가로, Goroutine Locality라고 고루틴이 다른 고루틴을 생성하는 일종의 스레드 계층 구조 지원과 비슷한 기능을 지원한다. 이 경우 발생할 수 있는 poor locality 문제를 해결하기 위해 시분할 상속(Time Slice Inheritance) 기법을 적용했다.
- 또한 모든 M의 local runqueue에 하나 이상의 고루틴이 존재하여 Global Runqueue의 기아상태가 발생할 가능성을 대비하여 loacal runqueue의 polling이 일어날 때마다 ++되는
schedtick이라는 변수를 계속해서 살피고, 이것의 값이 61이 될 때 Global runqueue를 반드시 polling해서 고루틴을 가져오도록 했다. 61을 기준으로 삼는 이유는 컴퓨터 시스템에서 소수를 이용하는 그 이유가 맞고, 하필 저 소수인 이유는 성능상 가장 괜찮은 성능을 보여줘서 그렇다. 즉, 수학적 이유와 경험적 이유가 맞물려서 선택된 값이 61이다. - 만약 고루틴에서 시스콜이 발생해 이를 담당하고 있던 M이 block 상태로 들어간다면, Go Shecduler는 이 M이 가지고 있던 P를 다른 M에게 건네줌으로써 시스콜을 기다릴 필요 없는 local runqueue 내의 다른 고루틴들의 실행을 보장한다. 이 행위 자체가 상당히 큰 리소스를 요하기 때문에, Go Scheduler는 긴 시간이 걸리는 system call이 발생했을 때에만 이런 hand off를 수행한다. 그 외의 짧은 system call들은 그냥 기다리게 내버려두고…
- 물론 이 시스콜이 짧을 거라 생각했는데 너무 오래 걸린다면 고루틴들을 모니터링하고 있던 sysmon에게 걸려서 handoff가 실행된다.
- OS단의 스레드 관리를 왜 굳이 고 언어 시스템에서 비슷하게 구현해 두었는가? 라는 생각이 들었는데, 일단은 효율성을 최대화한 OS단의 스레드 관리에 대해 더 큰 효율성과 사용자 입장에서 더 직관적인 스레드 관리 기능을 구현하고 싶었던 게 첫째 이유 같고…. 둘째로는 크로스 컴파일이 가능하도록 하기 위해서가 아닌가 싶다. 언제까지나 추측이라 정확한 건 아니다.
0.1.3. 표준 라이브러리
- go 바이너리를 분석하다 보면
runtime으로 시작하는 함수명이 많이 보일 것이다. - 이는 go가 기본으로 제공하는 표준 라이브러리
runtime하위에 있는 패키지와 함수이다. - 즉, 그렇기 때문에 정적 분석 시 굳이 들여다볼 필요 없는 함수이기도 하다.
- 라이브러리 개념을 빼고 보면 runtime은 JAVA의 JVM이나 파이썬의 인터프리터와 같은 개념을 하는, 프로그램을 실행될 수 있도록 하는 환경을 의미한다. 즉 이 안에 동시성 지원, 가비지 컬렉션, 동적 데이터 구조의 메모리 관리 등이 다 포함 및 구현된 채로 실행되는 것이다.
0.2. Go PE 섹션
Go PE는 전통적인 PE와 그 섹션 헤더 상에서는 차이가 없다고 보아도 무방하다.
즉, 헤더만으로는 그 둘을 구분할 수 없다.
Go PE의 헤더상에서 Go runtime과 관련된 문자열이 노출될 수도 있으나, 이는 Obfuscation 등의 기법을 거치면 찾기 어려워진다.
오히려 정적 분석 툴을 켜서 내부 내용을 확인하면
- 수상할 정도로 함수가 많고
- 뭔가 커널 단 동작을 제어하는 것 같은 함수들이 자꾸 스스로를 콜하며 끝나고
하는 것이 보이기 때문에, 바로 Go 바이너리라는 것을 알 수 있다.
1. prob.exe 리버싱
리버싱을 하는 이유는 뭘까?
- 파일의 목적을 알기 위해
- 즉, 이 파일이 어떤 행위를 하는지 알기 위해
- 더 디테일하게는 누구와 통신하여 어떤 방식으로 내부 루틴을 수행하는지 알아내 특징점을 추출하거나 원하는 대응을 하기 위해
사실 이게 다지 않을까?
그럼 이 이유를 충족하기 위해 분석가는 어떤 행위를 해야 할까?
- 먼저 샌드박스에서 돌려본다.
- 네트워크상으로 무엇을 하는지
- 어떤 DLL이나 외부 응용을 콜하는지
- 파일 시스템에서는 무엇이 변경되었는지
- 레지스트리 키에서는 무엇을 변경했는지 등을 알 수 있게 된다.
- 그러나 악성 코드가 샌드박스를 탐지하여 정상 행위를 하는 경우도 있고, 샌드박스로는 행위의 결과만을 알 수 있기 때문에 더 많은 정보를 얻기 위해서는 정적으로 접근해야 한다.
- 정적으로 접근할 땐 무엇이 핵심적인 기능을 수행하는 부분인지를 알아내는 것이 목적이다.
- 즉, 1의 샌드박스 분석을 통해 알아낸 행위 중, 추가적인 추적이 필요한 부분을 분석해 내부 루틴을 밝히는 것이 목적이다.
- 이를 통해 랜섬웨어의 경우에는 암호화 루틴 해독, 에이전트의 경우에는 C2 추적 등을 할 수 있다.
- 추가적으로 내부 함수 네이밍 규칙이나 시스템 콜 사용 습관 등을 통해 공격자를 라벨링할 수도 있다.
- 그러나 내부 문자열 디코딩 후 사용과 같은 루틴이 너무 복잡해 이걸 복호화하는 루틴을 짜다가는 시간이 너무 소요될 것이란 판단이 드는 때가 있다.
- 이럴 때 동적 분석을 수행한다.
- 메모리에 올라간 값의 변화, 실시간으로 서버에서 받아오는 값 등을 추적할 수 있다.
물론 저 순서대로 깔끔하게 떨어질 리는 없고, 2 했다가 3 했다가 5했다가 하는 거긴 한데…
아무튼 위와 같은 행위를 위해 다양한 테크닉이 필요하고, 이 모든 것을 종합해 리버싱이라 부르는 것이라 생각한다.
1.0. 샌드박스 분석
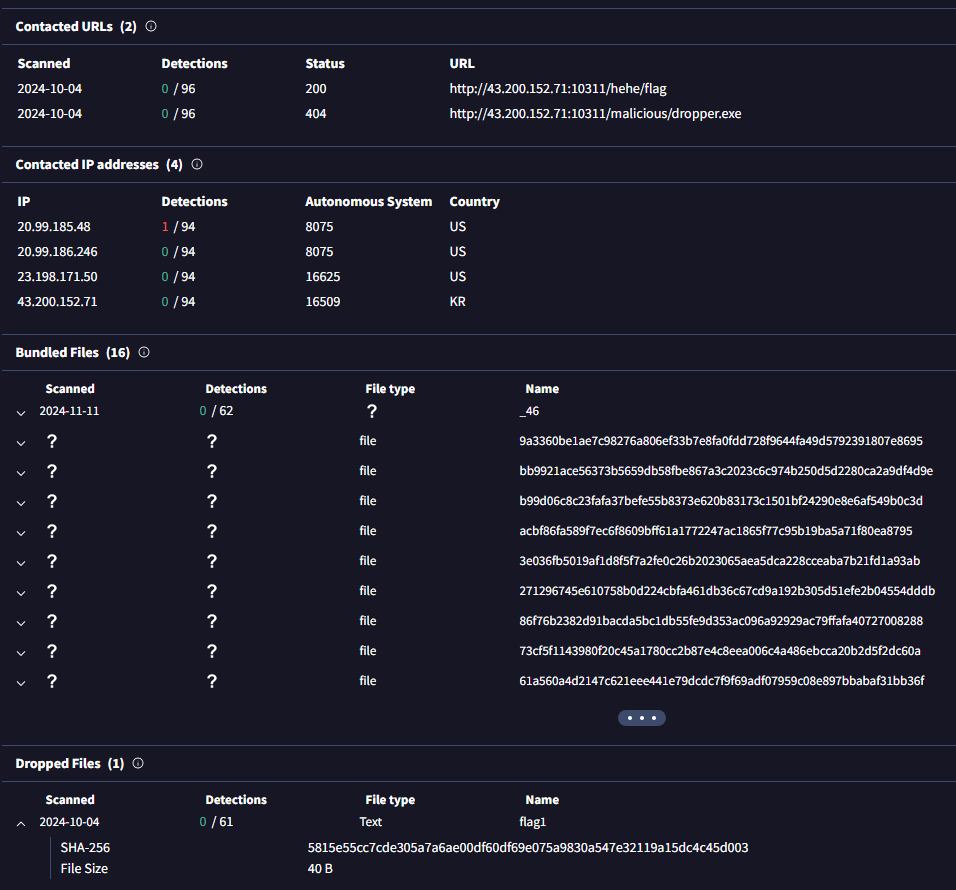
이러면 솔직히 KTX 타고 지나가다 봐도 flag url에 접속해 얻는 flag1 파일에 플래그가 적혀 있을 것 같긴 하다
그리고 실제로 그랬고
하지만 나는 이 문제를 통해 리버싱을 공부하는 게 목표니까, 정적-동적 분석까지 해 보려 한다.
1.1. 동적 분석 시도
해당 파일에 x64dbg 물려보려 시도하면 디버거가 바로 죽음
정적으로 까보기 위해 IDA에 띄워봄
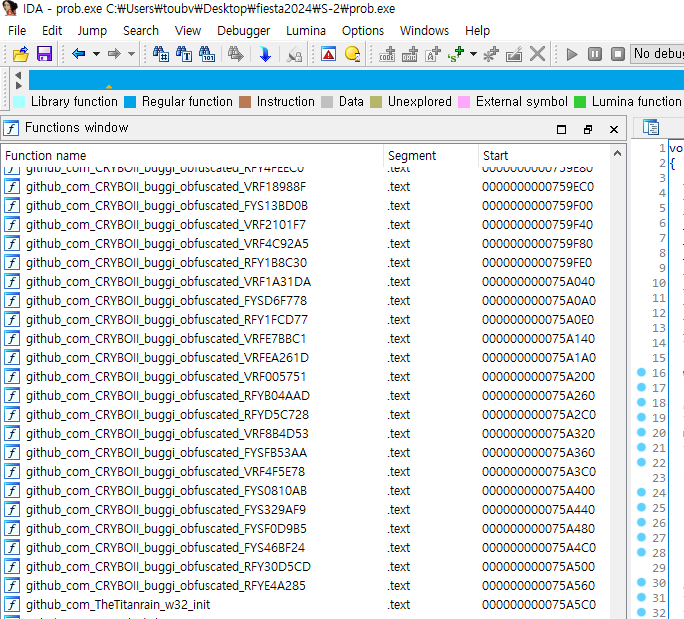
위와 같은 깃헙 오픈소스를 사용한 것이 보임
해당 오픈소스는 golang으로 작성된 안티디버거
인터넷에 검색해 해당 안티디버거의 레포로 들어가 보았다.
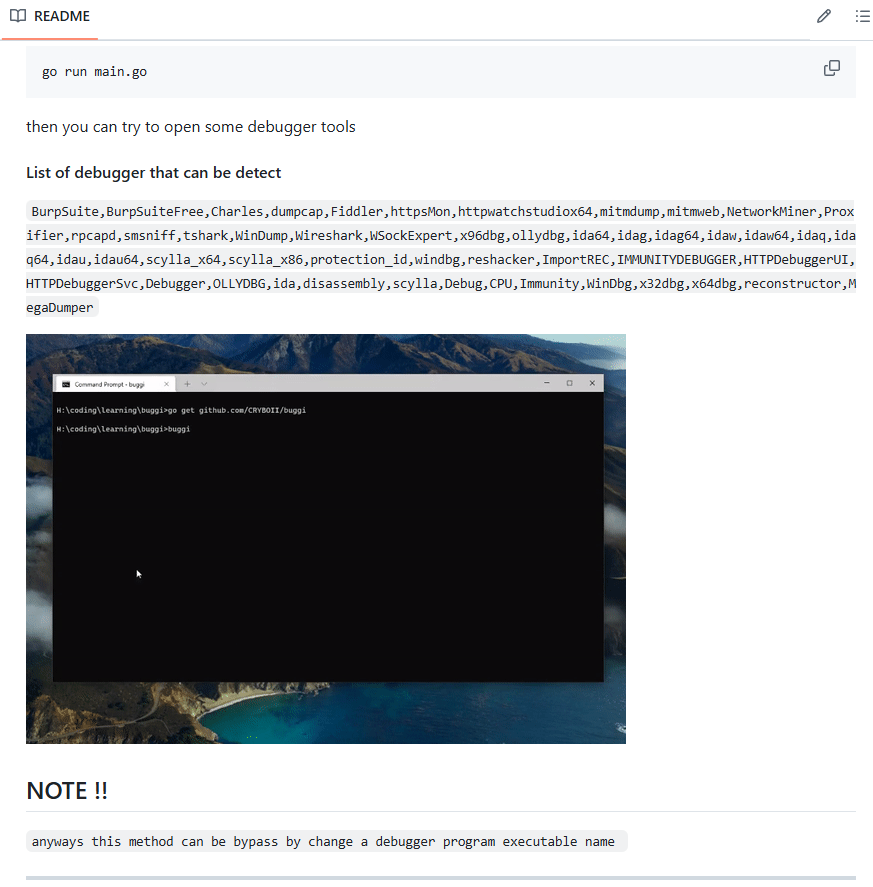
대박 탐지하는 디버거에 치트엔진이 없네
그리고 디버거 프로그램명을 기반으로 탐지하는 거라 exe name을 바꾸면 탐지 못 한다고도 쓰여 있다.
==있으나마나한 안티디버거
1.2. 정적 분석 시도
non-stripped된 바이너리이기 때문에, 내부 패키지와 그 내부의 함수도 복구가 가능하다.
특히, Golang으로 프로그램을 작성한다면 반드시 main 패키지가 존재해야 하며, 그 내부에 main 함수가 정의되어야 정상 컴파일이 가능하기 때문에, main 패키지에 대한 메타데이터 습득에서부터 분석을 시작하는 것이 좋을 것이다.
main패키지 하위 함수는 원래 go 컴파일 과정에서 main.{함수명}으로 네이밍되기 때문에(IDA에서는 .을 으로 해석하는 바람에 main{함수명}이 되지만), functions window에서 main_으로 검색해 보면 아래와 같은 결과가 나온다.
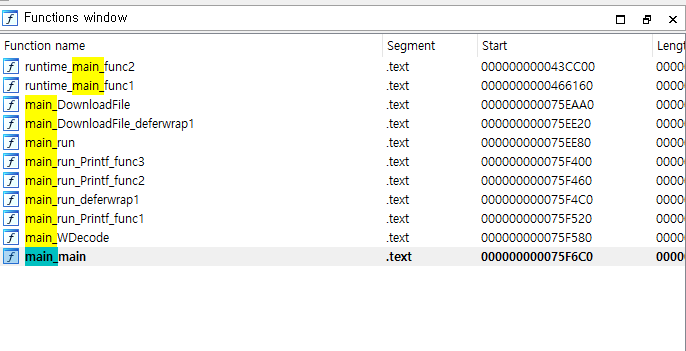
즉, main 패키지에는 아래와 같은 함수들이 정의되어 있던 것으로 보인다.
mainWDecoderunrun_deferwrap1run_Printf_func1run_Printf_func2run_Printf_func3DownloadFileDownloadFile_deferwrap1
main 패키지의 엔트리는 main함수이니, 그로부터 콜 관계를 분석해 보기로 했다.
1.3. main 패키지 내 함수 간 콜 관계 분석
어떤 함수가 진짜 핵심 기능을 수행하는 함수인지 알고 싶다면, 이렇게 non-stripped 되어있고 엔트리가 확실한 바이너리라면 콜 관계를 분석해서 접근하는 게 좋다고 생각한다.
라고 말하면서 function calls 그래프 띄우려고 한 여섯번정도 요청 날렸는데
그래프가 안 떠서 생각해 보니 이 바이너리는 함수가 한 만 개 정도 되는 바이너리였고
큰일났음을 눈치챘을 땐 이미 컴퓨터가 죽은 뒤였다
다들 golang 프로그램을 분석할 땐 조심하도록 하자
이것들은 컴퓨터 암살자다
이상.
은 무슨… 리버싱은 노가다다
그래서 수동으로 분석했다.
open subviews → function calls를 보더라도 알 수 없는 게 있다. 예를 들어 lea rcx, {function} 이후에 call rcx 가 오는 경우가 그렇다.
그래서 교차검증을 진행해 최대한 완전하게 콜관계를 분석했다.
- main
- call
- WDecode
- xref
- 없음(runtime에서 콜함)
- call
- WDecode
- call
- 없음
- xref
- main
- run
- call
- run
- call
- WDecode
- DownloadFile
- run_Printf_func2
- run_deferwrap1
- run_Printf_func1
- run_Printf_func3
- xref
- run
- call
- run_deferwrap1
- call
- 없음
- xref
- run
- run_deferwrap1
- call
- run_Printf_func1
- call
- 없음
- xref
- run
- call
- run_Printf_func2
- call
- 없음
- xref
- run
- call
- run_Printf_func3
- call
- 없음
- xref
- run
- call
- DownloadFile
- call
- DownloadFile_deferwrap1
- xref
- run
- call
- DownloadFile_deferwrap1
- call
- 없음
- xref
- DownloadFile
- call
위 결과를 보면, main_run이 가장 핵심 함수인 것으로 보인다.
그러나 궁금한 점, 대체 뭐가 main_run을 콜하는 걸까? 사실 모르겠음… main_main이 엔트리인데 왜 main_run과 main_main 간의 관계는 안 보이는 거지?
이건 동적 분석하면서 알아보기로 했음
은 그냥 원라인 디버깅하면 알수있을듯…
1.4. 동적 분석
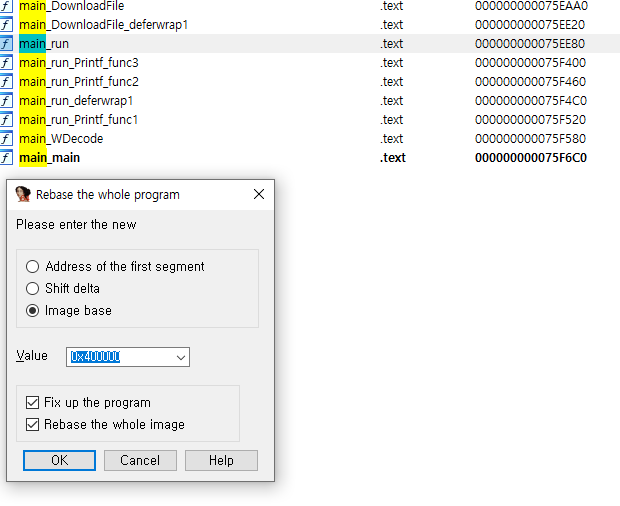
일단 함수 오프셋을 계산하기 위한 기본 정보 세이브해두고
Cheat Engine에서 prob.exe를 실행시키거나, 실행중인 prob.exe에 attach하거나 해야 하는데
전자는 안됨 왜 안될까
후자는 cmd에서 실행하면 됨
그러나 IDA를 켠 채로 후자를 시도하면 안티디버거에 걸리기 때문에 prob.exe가 바로 죽어버림
즉 치트엔진을 붙일 수 없음
따라서 IDA를 끄고 하시길 바랍니다

0x75ee80이 main_run 함수의 시작 주소였고 베이스는 0x400000
그럼 오프셋은 0x35ee80
1.4.1. 실패 기록
치트엔진으로 별짓을 다했음
-
cmd에서 exec되는 흐름을 보고 싶어서 x96dbg 붙였음
→ cmd는 권한 문제로 디버깅이 어려움
-
그래서 한 생각: prob가 콜하는 dll을 전부 확인하자
→ 사유: 얘가 지금 http 통신 열려다가 server가 안 열어줘서 오류가 나고 죽는 거니까, http 통신의 오류를 담당하는 dll을 따라가면 bp를 걸 수 있겠지
prob가 콜하는 dll 리스트
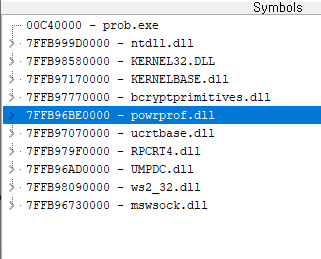
powerprof.dll: 머신의 전원에 관한 기능을 주관하는 dllucrtbase.dll: Universal C 런타임rpcrt4.dll: RPC를 지원하며, 보통 네트워크 및 인터넷 통신을 구현할 때 사용UMPDC.dll: 유저 모드에서의 전원 의존성 조정을 위해 사용됨ws2_32.dll: 소켓 통신에 사용됨mswsock.dll: TCP/IP 프로토콜을 통해 인터넷 통신을 하기 위해 사용됨
실패!!!!!!!
1.4.2. 성공!
그래서 다른 방법을 씀
프로그램을 보면 main_DownloadFile에 넘기는 파라미터 중 main_WDecode(…, main_encoded_filepath) 가 있음
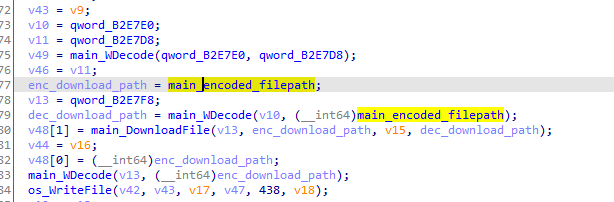
main_encoded_filepath는 static으로 정의된 문자열의 시작을 가리키는 포인터를 저장하고 있음
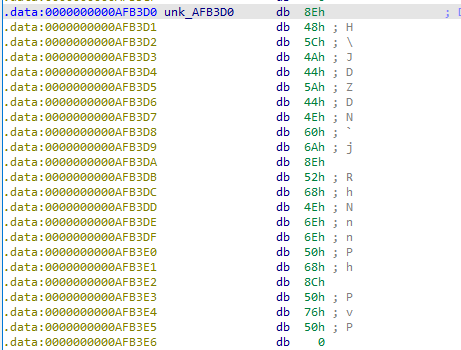
즉, 이 문자열이 Decoding을 거쳐서 어떤 문자열이 되는지 알아내면 되므로
위 문자열의 시작 주소에 어떤 인스트럭션이 접근하는지를 알아내면 그쪽에서 Decoding된 문자열을 알아낼 수 있을 것임
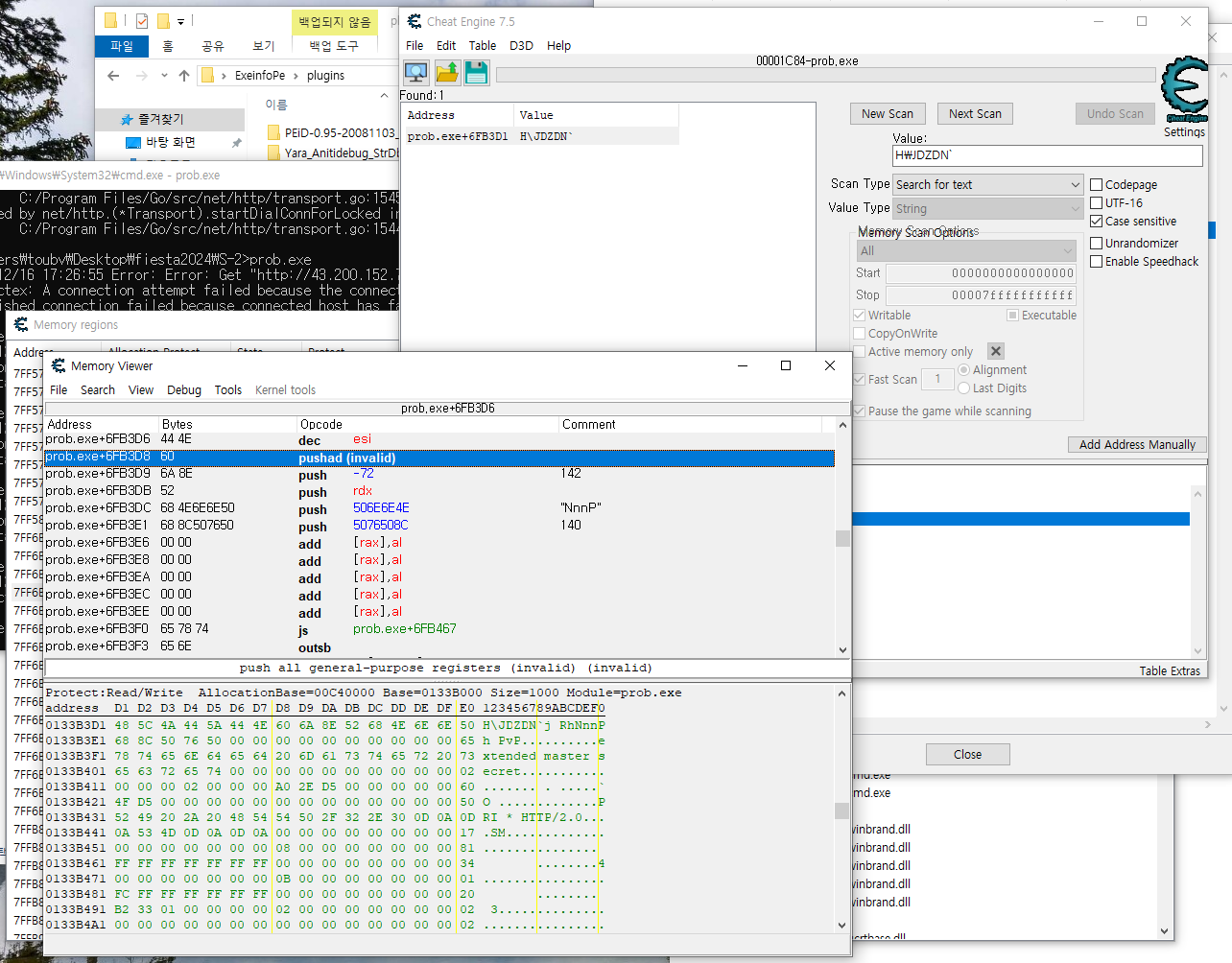
인간승리
ida상에서는 dec_download_path가 main_WDecode의 결과를 받는 것으로 나와 있기 때문에, 이게 메모리상의 어떤 부분에 있는지 확인해 보는 게 좋을 것 같음.
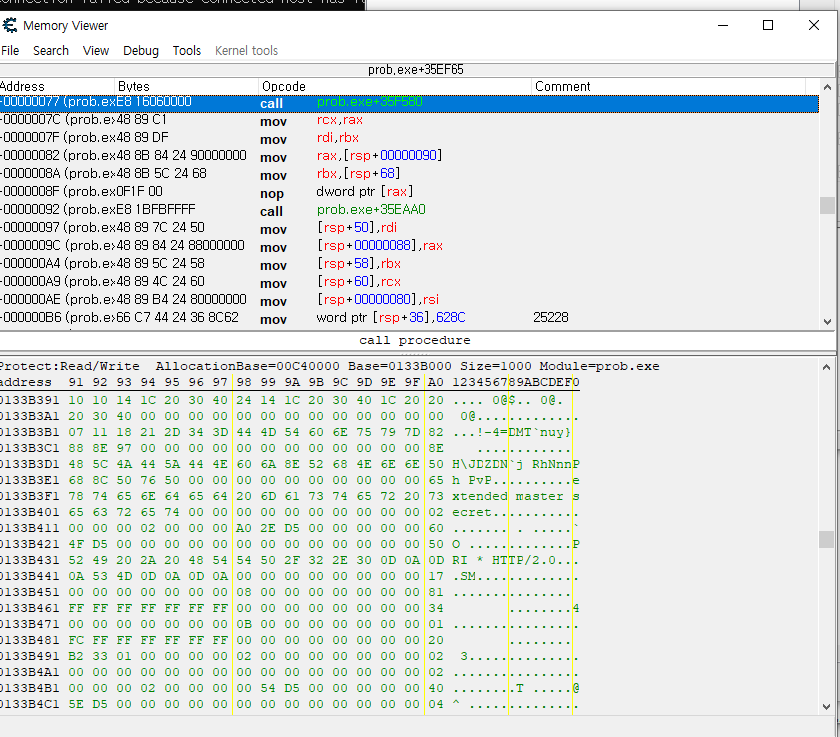
저기다가 bp걸고 메모리에 어떤 값이 왔다갔다하는지 알고싶은데
어떻게 해야 시작할 때부터 bp를 걸 수 있지?
→ 충분히 민첩하면 됨(원라인 디버깅)
따라서 lua 스크립트로 프로세스 실행한 다음 홀드 걸어놓고 디버거를 어태치해서 bp걸은 다음 메모리 뷰를 띄우도록 해 보았음
-- prob.exe 실행 및 브레이크포인트 설정
-- 파일 실행 및 프로세스 Attach
local processPath = "C:\\Users\\toubv\\Desktop\\fiesta2024\\S-2\\prob.exe" -- prob.exe의 절대 경로를 지정하세요.
local success = shellExecute(processPath) -- 프로그램 실행
-- 잠시 대기 (프로세스 실행 및 메모리 준비 시간 확보)
sleep(1000)
-- 프로세스에 Attach
local processName = "prob.exe"
if openProcess(processName) then
print("prob.exe 프로세스에 Attach 완료!")
else
print("프로세스를 찾을 수 없습니다. Attach 실패.")
return
end
-- 엔트리 포인트 주소 찾기
local modules = enumModules()
local baseAddress = nil
for i, module in ipairs(modules) do
if string.lower(module.Name) == processName then
baseAddress = module.Address
print(string.format("모듈 베이스 주소: 0x%X", baseAddress))
break
end
end
-- 엔트리 포인트에 브레이크포인트 설정
local entryPoint = baseAddress -- PE 헤더 분석이 필요하면 여기에 오프셋 추가
debug_setBreakpoint(entryPoint+0x35f580)
print(string.format("엔트리 포인트 (0x%X)에 브레이크포인트가 설정되었습니다.", entryPoint+0x35f580))
-- 메모리 뷰 띄움
openMemoryView()
치트엔진 안써봐서 메뉴부터 막 누르고 다녔는데
거기에서 lua script 보자마자 이걸 언젠가 쓰겠군 했음
그런데 이렇게 빠르게 쓰게 될 줄은 몰랐음
결과
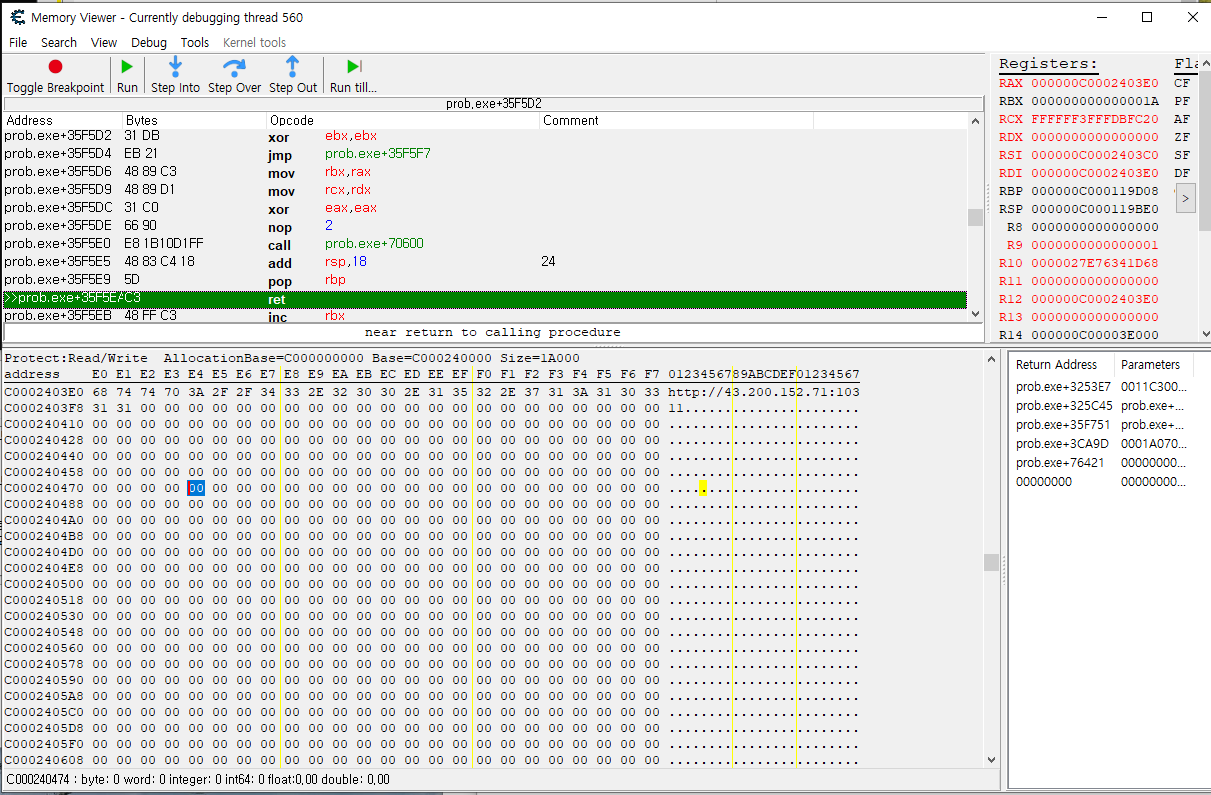
prob.exe+35f580은 dec_downloadPath에 파일 다운로드 경로를 저장하기 위해 main_WDecode를 콜하는 부분으로, 해당 과정을 거치고 나면 디코딩된 경로가 dec_downloadPath에 저장될 것임
go로 컴파일된 프로그램의 어셈블리 규칙에 따르면 함수의 리턴값은 레지스터에 저장될 확률이 높으니1 레지스터부터 확인해 보는 게 좋을 것 같았고, 레지스터 중 스택 및 힙에 할당된 메모리 영역(메모리 덤프에서 명시된 Base와 Size 감안할 때)에 포함되는 주소를 가진 레지스터를 하나하나 확인해 보니, http://43[.]200.152.71:10311 문자열을 확인할 수 있었음
추가로, 다음 루틴에서 콜하는 함수(main_downloadFile)를 따라간 다음 리턴값이 담긴 rax를 확인해 보니, 다음과 같은 문자열을 확인할 수 있었고
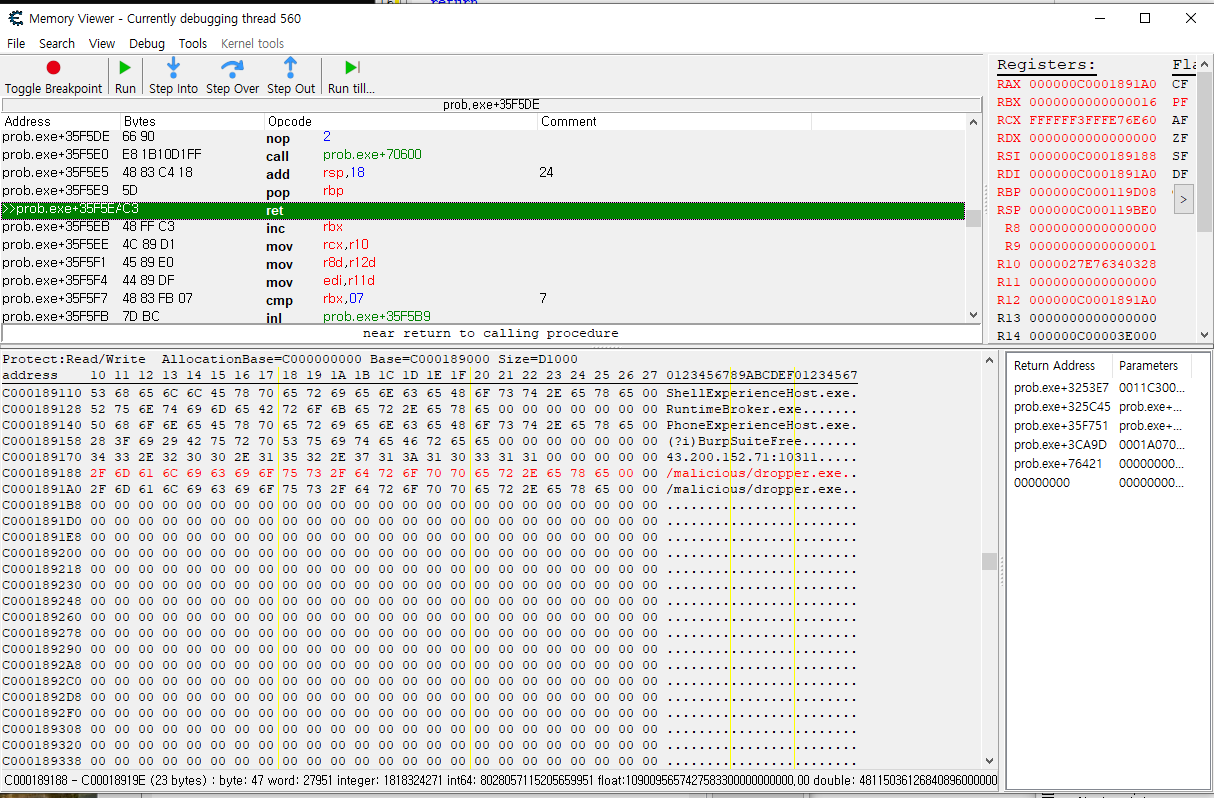
43[.]200.152.71:10311/malicious/dropper.exe
그 다음에 다시 한 번 콜되는 main_WDecode 함수가 무엇을 리턴하는지도 확인해 봄
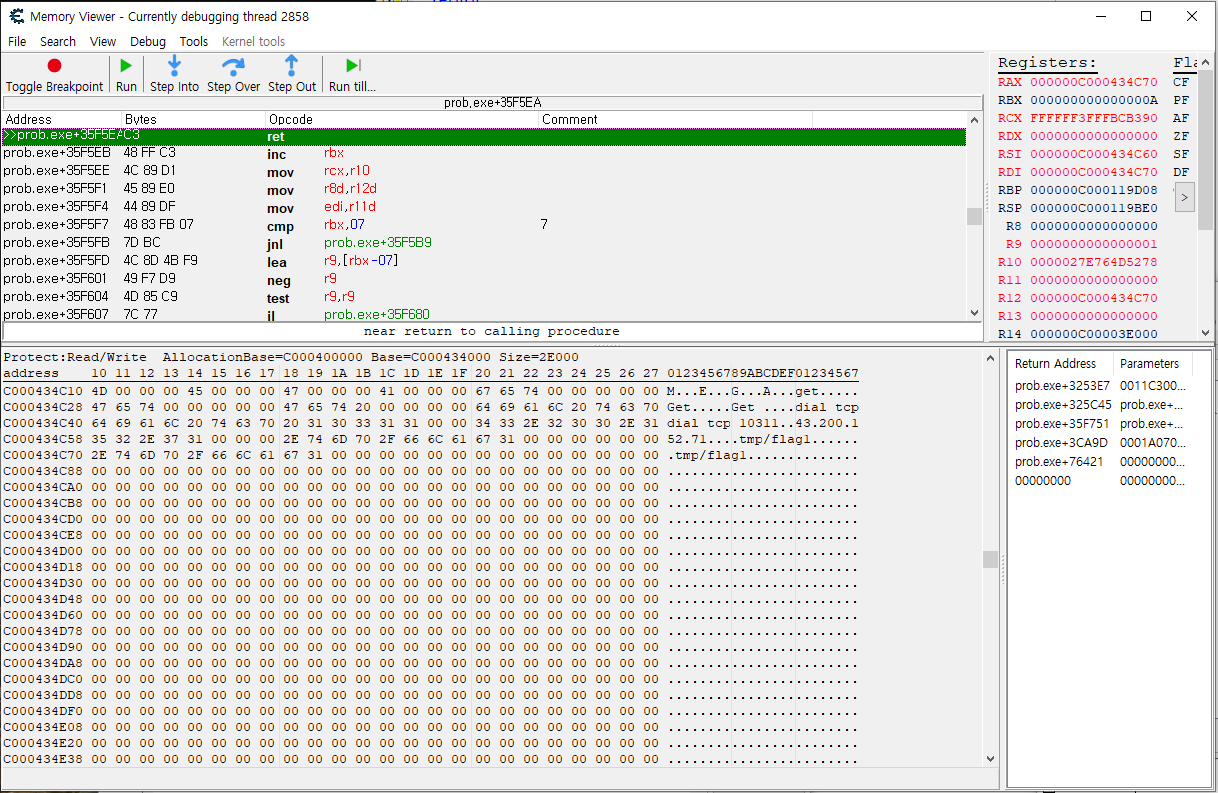
43[.]200.152.71:10311/tmp/flag1
즉, 총 2개의 파일을 2번의 요청에 걸쳐 요청한다는 걸 알 수 있었음
근데 사실 이런 건 샌드박스에 먼저 돌려보는 게 좋아서… 그리고 문제 파일에는 안티샌드박스가 안 걸려 있어서 돌리면 그냥 바로 나온다. 난 그렇게 풀었고…
2. 번외: IDA 오류 고치기
2.1. main_main 함수 분석
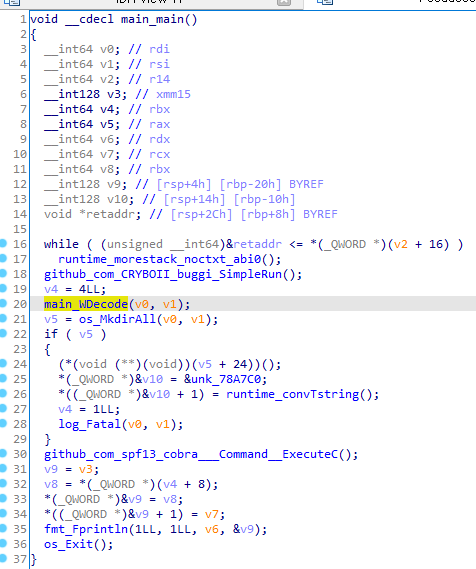
runtime_morestack_noctxt_abi0함수는 커스텀 함수가 아닌 것으로 추정됨(검색 결과 다른 대회의 리버싱 문제에서도 확인)github_com_CRYBOII_buggi_SimpleRun();함수는 안티디버거 함수 실행부- 따라서
main_WDcode(v0,v1)부터 분석 시작
2.2. main_WDcode(v0, v1) 함수 분석
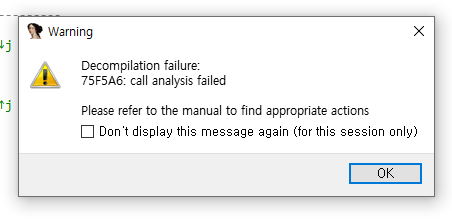
함수 호출을 잘못 인식한 결과라고 하니, 해당 라인으로 가서 함수 콜의 형태를 올바르게 고쳐줘야 한다.
main_WDcode(v0, v1)은 인자 2개를 받아서 시작main_WDcode내부에서rsp와 값을 상호작용하는machine관련 요소는rax,rbx레지스터 2개- 왜냐하면 함수는 외부에서 파라미터를 전달받으면 함수 내부에서 사용하기 위해 스택 프레임 내에 값을 전달해놓기 때문임
- 물론 이 점은 콜링 컨벤션이 달라지면 달라지겠지만, 어쨌든 저 2개 레지스터가 수상한 건 맞음
-
문제가 발생한
0x75f5a6라인에서는 아래와 같이 함수를 콜하고 있었음.text:000000000075F580 cmp rsp, [r14+10h] .text:000000000075F584 jbe loc_75F686 .text:000000000075F58A push rbp .text:000000000075F58B mov rbp, rsp .text:000000000075F58E sub rsp, 18h .text:000000000075F592 mov [rsp+18h+arg_8], rbx .text:000000000075F597 mov [rsp+18h+arg_0], rax .text:000000000075F59C mov rcx, rbx .text:000000000075F59F lea rax, qword_78A840 .text:000000000075F5A6 call runtime_makeslicemain_WDcode는int64타입 param을 2개 받고, 스택 내부 공간 할당 시sub rsp, 18h를 통해 18h만큼의 공간을 할당받음
-
문제의
runtime_makeslice함수가 실행 초반에 어떻게 파라미터를 처리하는지 확인하면 다음과 같음.text:000000000046FAE0 cmp rsp, [r14+10h] .text:000000000046FAE4 jbe loc_46FB7F .text:000000000046FAEA push rbp .text:000000000046FAEB mov rbp, rsp .text:000000000046FAEE sub rsp, 18h .text:000000000046FAF2 mov rdx, [rax] .text:000000000046FAF5 mov rsi, rax .text:000000000046FAF8 mov rax, rdx .text:000000000046FAFB mov rdi, raxruntime_makeslice함수는 스택 내부 공간 할당 시sub rsp, 18h를 통해 18h만큼의 공간을 할당받으며, 이후 이어지는 스택 공간 관련 연산이 없음- 즉,
runtime_makelice또한 int64 타입 param을 2개 받으리란 추측이 가능함 - 따라서 해당 함수 type declaration을 통해
__int64 __fastcall runtime_makeslice(__int64, __int64);로 재선언 진행
-
그 결과, 아래와 같이 함수 재조정이 올바르게 되어 디컴파일이 가능해짐

-
Function calls pass arguments and results using a combination of the stack and machine registers. Each argument or result is passed either entirely in registers or entirely on the stack. Because access to registers is generally faster than access to the stack, arguments and results are preferentially passed in registers. However, any argument or result that contains a non-trivial array or does not fit entirely in the remaining available registers is passed on the stack. ↩
